JPA JpaRepository 메소드 (save(), find~())
JPA 기초 제목을 JPA 기초라고 하긴 했으나 이 포스팅에서는 정말 기본적인 설정과 어노테이션 정도만 포스팅. 예제 환경 Intelli J SpringBoot 2.6.2 Lombok Gradle 7.3.2 JPA는 의존성 추가를 해야 사용할 수
myyoun.tistory.com
이전 작성한 포스팅에서의 save, find~ 말고 나머지 메소드들에 대한 포스팅.
위 포스팅에서와 동일한 프로젝트 환경으로 진행.
- Intelli J
- SpringBoot 2.6.2
- Lombok
- Gradle 7.3.2
이 포스팅에서는 아래의 메소드들을 정리.
- count()
- existsById()
- delete()
- deleteById()
- deleteAll(), deleteAllById()
- deleteInBatch()
- deleteAllInBatch(), deleteAllByIdInBatch()
그리고 저번 포스팅과 동일한 Entity와 Repository를 사용.
@Data
@NoArgsConstructor
@AllArgsConstructor
@RequiredArgsConstructor
@Entity
public class User{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NonNull
private String name;
@NonNull
private String email;
}public interface UserRepository extends JpaRepository<User, Long>{
}
count()
count() 메소드는 의미 그대로 데이터의 개수를 의미한다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
long count = userRepository.count();
System.out.println(count);
}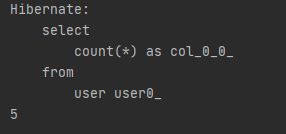
매핑된 테이블에 존재하는 데이터의 개수를 조회하는 메소드이다.
그리고 count() 메소드의 경우 return 타입이 long타입이기 때문에 long으로 받아야 한다.
existById()
exsistById는 해당 Id(Primary key) 값에 해당하는 데이터가 존재하는지에 대해 나타낸다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
boolean exists = userRepository.existsById(1L);
System.out.println(exists);
}처음 테스트 실행하기 전에는 boolean타입이라 어떻게 조회할지 궁금했다.
근데 의외로 select쿼리릍 통해 해당 id 값을 갖고 있는 데이터의 개수를 조회한다.
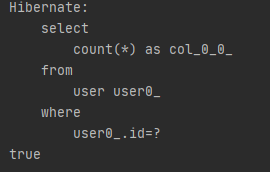
즉, 해당 쿼리를 실행시켜 결과값이 0이면 false, 0이 아니면 true가 된다.
그리고 JPQL에서만 해당하는 것인지는 모르겠지만 해당 데이터가 존재하는지 유무에 대해 count()보다 existsById()를 사용하는것이 더 좋다는 포스팅을 봤다.
내용은 다음과 같았다.
데이터가 존재하는지를 확인하기 위해 count를 사용할 때가 있다.
count의 경우 총 개수를 확인해야 하기 때문에 존재유무와 상관없이 일단 모든 데이터를 훑어보게 된다.
하지만 exists의 경우 데이터가 존재하는지만 확인하면 되기 때문에 데이터를 찾는 순간 쿼리를 종료하게 된다.
그럼 당연히 존재유무만 확인하기 위해서는 count보다는 exists가 성능이 더 좋을 수 밖에 없다 라는 내용이다.
이 포스팅은 아래 Reference에서 확인.
delete()
삭제 메소드이다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
User user = userRepository.findById(1L).orElseThrow(RuntimeException::new);
userRepository.delete(user);
userRepository.findAll().forEach(System.out::println);
}
여기서 주의해야할 점은 상황에 따라 달라지겠지만 위 예제처럼 진행하는 경우 findById().orElse() 보다는
findById().orElseThrow가 좀 더 낫다.
delete의 경우 CrudRepository에서 확인해보면 'entity must not be {@literal null}.' 이라고 있는것을 볼 수 있는데
null이 들어올 경우 문제가 발생한다는 것이다.
실제로 null을 넣어보면 IllegalArgumentException이 발생하는 것을 볼 수 있다.
그래서 그냥 orElseThrow로 null인 경우 Exception을 바로 발생시키게 하는것.
그냥 편의성 정도로 생각하면 될것같다.
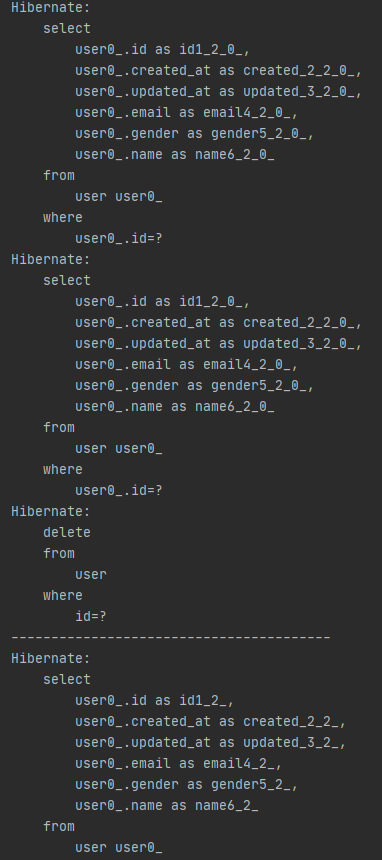
쿼리문은 이렇게 로그에 출력된다.
첫 select 는 findById()에 의해 실행된 select문이다.
그리고 그 아래에 select문이 한번 더 실행된것을 볼 수 있는데 delete()메소드의 경우 delete쿼리를 실행하기 전 select로 해당 데이터가 있는지 조회한 다음에 있으면 delete쿼리를 실행하기 때문이다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
//존재하지 않는 데이터를 만들기 위해 new로 생성
User user = new User();
user.setId(8L);
userRepository.delete(user);
userRepository.findAll().forEach(System.out::println);
}
그래서 위 코드처럼 현재 없는 아이디값을 넣어 테스트해보면 delete쿼리는 실행되지 않고 select쿼리까지만 실행되는것을 볼 수 있다.
deleteById()
delete() 메소드처럼 하나의 데이터를 지워준다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
userRepository.deleteById(1L);
userRepository.findAll().forEach(System.out::println);
}
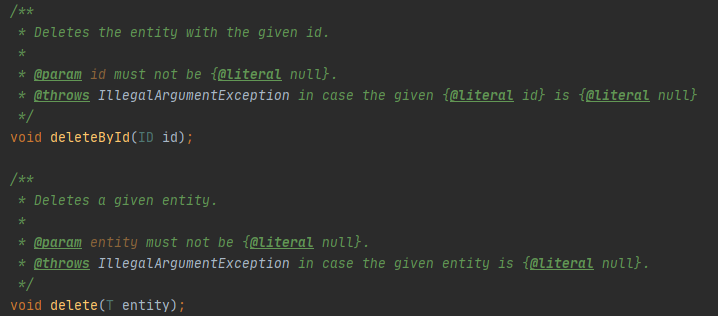
CrudRepository를 보면 delete() 메소드는 entity를 받는 반면 deleteById() 메소드는 메소드명처럼 id를 받는다.
결과는 delete() 메소드와 동일한 결과를 출력해준다.
쿼리문에서의 차이는 findById() 메소드를 사용하지 않기 때문에 delete 처리 하기 전 select문이 하나 줄어들었다는 정도다.
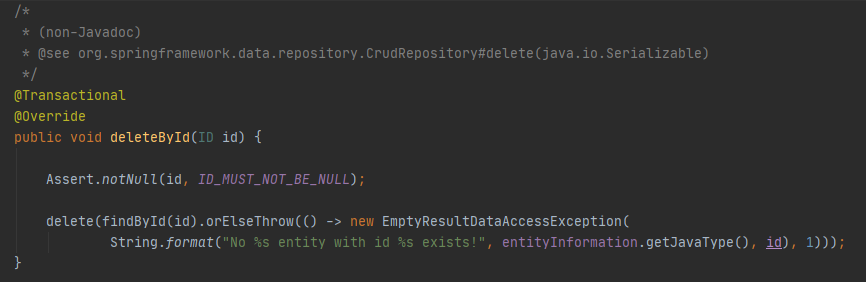
SimpleJpaRepository에서 deleteById를 보면 넘어온 id값으로 findById를 사용해 delete()에 넘겨줄 데이터를 조회하는데 데이터가 null인경우에는 EmptyResultDataAccessException을 발생시키고 존재하는 경우 delete()에 id값을 인자로 호출하고 있다.
그럼 결국 delete() 메소드 처리과정과 동일하다고 볼 수 있게 된다.
userRepository.delete(userRepository.findById(1L).orElseThrow(EmptyResultDataAccessException::new);
이전 delete()메소드 예제에서의 이 과정을 deleteById() 내부에서 처리하고 있다고 볼 수 있다.
그럼 delete() 메소드나 deleteById() 메소드나 결국 처리과정이 동일하다고 볼 수 있는데 나눠져 있는 이유는?
findById()에서의 차이가 있다고 볼 수 있다.
delete 메소드는 해당 예제에서처럼 findById랑 조합해서 사용하는 경우가 많다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
//delete
userRepository.delete(
userRepository.findById(1L).orElseThrow(RuntimeException::new)
);
// deleteById
userRepository.deleteById(1L);
}이렇게 사용하는 측면에서만 보면 delete() 메소드는 직접 findById()와의 조합을 직접 작성해 사용하는 형태고
deleteById()는 메소드 내부에서 예외처리를 해주고 Id값만 넘겨주면 되는 차이가 있다.
그럼 굳이 나눠서 사용하는 방법을 알아야 하는 이유는 지금은 계속 포스팅에서 orElseThrow를 통해 null인 경우
RuntimeException을 발생시키도록 하고 있지만 필요에 따라 예외처리를 custom해서 처리할 수 있다는 장점이 있다.
하지만 deleteById() 메소드를 사용하면 예외처리를 커스텀하는것이 아닌 EmptyResultDataAccessException이 발생하기 때문에 예외처리에서의 차이점이 발생한다고 볼 수 있다.
이 차이에 대한 포스팅은 Reference에서 확인.
deleteAll(), deleteAllById()
deleteAll() 메소드는 테이블의 모든 데이터를 삭제하는 메소드다.
쿼리문으로만 보면 DELETE FROM user; 의 형태.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
userRepository.deleteAll();
}
사용은 이렇게 사용한다.

하지만 CrudRepository를 보면 entities를 인자로 받아 삭제가 가능하다는 것을 볼 수 있다.
즉, 원하는 데이터만 삭제하는것도 가능하다는 것이다.
사용은 saveAll()를 했을때와 동일하게 사용한다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
User user1 = new User();
user1.setId(1L);
User user2 = new User();
user2.setId(2L);
userRepository.deleteAll(Lists.newArrayList(user1, user2));
List<User> users = userRepository.findAllById(Lists.newArrayList(1L, 2L));
userRepository.deleteAll(users);
}이 예제처럼 복수의 entity를 넘겨 처리하는 메소드이다.
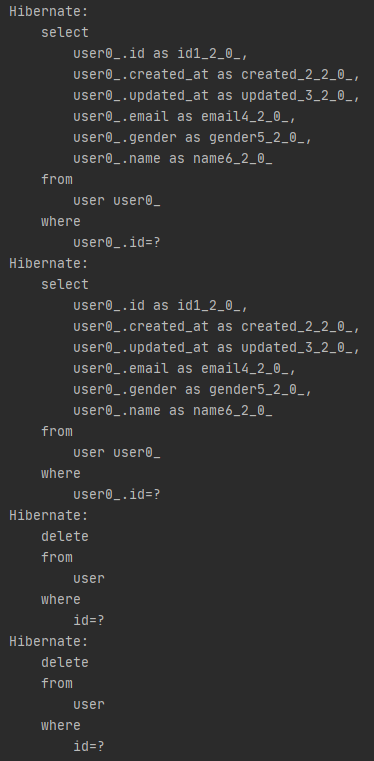
쿼리문을 살펴보면 deleteAll이 실행될 때 넘겨받은 Entity의 개수만큼 select문으로 조회를 하고
그 다음 그 데이터들을 하나하나 삭제해 나간다.

deleteAll 역시 SimpleJpaRepository에서 확인할 수 있는데 받은 Entity들을 반복문을 통해 delete로 넘겨주는것을 볼 수 있다.
그리고 delete에서는 isNew로 체크하기 때문에 만약 넘겨받은 Entity 중에서 하나는 존재하지만 하나는 존재하지 않는 데이터라면 select문과 delete문 모두 한번씩만 수행하게 된다.
그리고 이와 동일한 결과를 출력하는 메소드가 deleteAllById() 메소드인데 일단 사용할때의 차이는 entity를 받느냐
Id를 받느냐의 차이다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
userRepository.deleteAllById(Lists.newArrayList(1L, 2L));
List<Long> ids = new ArrayList<>();
ids.add(1L);
ids.add(2L);
userRepository.deleteAllById(ids);
}일단 이렇게 표면적인 차이에서는 Id값을 받아 처리한다는 차이만 보인다.
그리고 SimpleJpaRepository에 들어가서 확인해보면 deleteAll()은 delete()를 호출해 처리한 반면

deleteAllById는 deleteById()를 호출하는것을 볼 수 있다.
즉, null에 대한 예외처리가 된다는 것을 볼 수 있다.
deleteAll()과 deleteAllById()를 묶은 이유가 여기 있다.
deleteAllById() 메소드는 강의에서도 설명이 전혀 없이 넘어갔기 때문에 따로 찾아보려 했으나
포스팅 자체가 별로 없다.
좀 뜯어보니 delete() 메소드와 deleteById() 메소드의 차이점과 비슷했기에 다행..
그럼 deleteAll()과 deleteAllById()의 경우 표면적으로만 봤을때 발생하는 차이가 일단 Entity를 받느냐
id를 받느냐의 차이다. 물론 둘다 List로 처리하지만 deleteAll은 Entity타입의 List, deleteAllById는 Id 타입의 리스트를 받게 된다.
출력하는 쿼리문 역시 동일하게 처리되지만 지금까지 확인한 것으로는 deleteAll() 메소드의 경우 존재하지 않는 데이터에 대한 delete() 요청은 무시한다.
Exception을 발생하지 않고 delete 쿼리역시 동작하지 않는다는것.
하지만 deleteAllById()의 경우 deleteById()를 호출하도록 되어있기 때문에 존재하지 않는 데이터에 대해
deleteById() 처리에서 처럼 EmptyResultDataAccessException을 발생시킨다.
좀 다시 정리하자면
deleteAll()은 Entity를 받아 처리하면서 존재하지않는 데이터에 대한 요청은 무시하지만
deleteAllById() 메소드는 Id값을 받아 처리하고 존재하지 않는 데이터에 대해 EmptyResultDataAccessException을 발생시킨다.
이정도..?
deleteInBatch()
deleteInBatch() 메소드는 Entity를 받아 처리하는 deleteAll() 처럼 entity타입의 리스트를 받아 처리한다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
List<User> users = userRepository.findAllById(Lists.newArrayList(1L, 2L));
userRepository.deleteInBatch(users);
}
deleteAll()과의 차이점으로는 select로 조회하지 않고 한번에 delete 처리를 한다는 것이다.
deleteAll()의 경우는 2개의 데이터를 삭제할 때 해당 데이터가 존재하는지 select 쿼리를 2번 진행한 다음
delete쿼리 역시 2번을 진행했다.
즉, 총 4번의 쿼리문이 실행이 되는데 deleteInBatch() 메소드의 경우 딱 한번의 delete쿼리만 실행된다.

아무래도 deleteAll()을 통해 여러 데이터들을 삭제하고자 한다면 데이터의 수 * 2 만큼 쿼리가 실행되기 때문에
성능이슈가 발생할 수 있다.
하지만 deleteInBatch()의 경우 delete쿼리 한번만을 실행하기 때문에 좀 더 낫다고 볼 수 있다.
그리고 deleteInBatch() 메소드는 인자 없이 그냥 사용할수는 없다.
deleteInBatch()를 사용하게 되면

이렇게 줄이 생기는것을 볼 수 있는데 내용을 보면 'deleteInBatch(java.lang.Iterable<T>)' is deprecated 라는 설명을 볼 수 있다.
더 사용되지 않는다는 의미.
Jpa Document를 보더라도
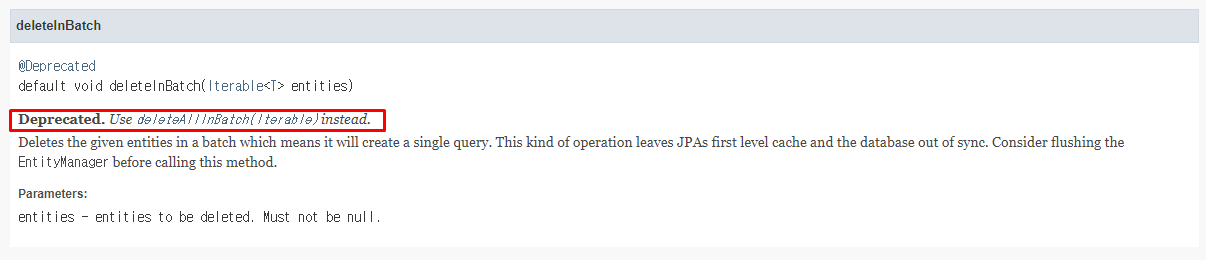
이렇게 더이상 사용되지 않으니 deleteAllInBatch()를 사용하라고 되어있다.
그럼에도 처리가 되긴 하는 이유는 아래에 있다.
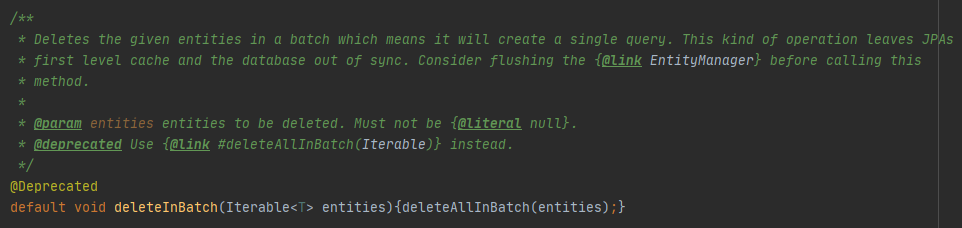
JpaRepository를 보면 deleteInBatch는 deleteAllInBatch()를 바로 호출하면서 자신이 받은 인자를 그대로 넘겨준다.
결국 deleteInBatch() 메소드는 거쳐가는곳일 뿐 deleteAllInBatch() 메소드에서 처리하게 된다.
deleteAllInBatch(), deleteAllByIdInBatch()
deleteAllInBatch() 메소드는 deleteAll() 메소드와 사용방법이 아예 동일하다고 할 수 있다.
deleteInBatch()는 인자를 꼭 받아야 하는 반면 deleteAllInBatch() 메소드는 deleteAll() 메소드처럼 인자를 받지 않게 되면 테이블의 모든 데이터를 삭제하게 된다.
차이점은 deleteInBatch() 메소드에서의 설명과 동일하게 삭제처리 이전에 조회하는 과정이 없고 delete 쿼리를 한번만 실행한다는 점이다.
사용은 아래와 같이 한다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
userRepository.deleteAllInBatch();
List<User> users = userRepository.findAllById(Lists.newArrayList(1L, 2L));
userRepository.deleteAllInBatch(users);
}
복수의 데이터를 삭제하고자 한다면 계속 조회하고 하나하나 지워나가는 deleteAll() 메소드보다는 따로 조회하지 않고 한번의 delete 쿼리를 실행하는 deleteAllInBatch()가 성능이 좋을 수 밖에 없다.
deleteAllByIdInBatch()를 같이 묶어둔 이유는 동일한 처리를 하지만 약간의 차이가 존재하기 때문이다.
deleteAllInBatch()는 deleteAll()과 마찬가지로 entiteis를 받아 처리하지만 deleteAllByIdInBatch()는 deleteAllById() 메소드처럼 Id를 받아 처리한다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
List<Long> ids = new ArrayList<>();
ids.add(1L);
ids.add(2L);
userRepository.deleteAllByIdInBatch(ids);
userRepository.deleteAllByIdInBatch(Lists.newArrayList(1L, 2L));
}이런 형태로 사용하게 된다. 그리고 deleteAllByIdInBatch는 인자를 꼭 받아야 한다.
deleteAll()과 deleteAllById()는 예외처리를 하느냐 안하느냐에서 차이가 발생했는데
deleteAllInBatch()와 deleteAllByIdInBatch()는 예외처리에서의 차이가 아닌 쿼리문에서 차이가 발생한다.
delteAllInBatch()의 경우 delete 쿼리를 생성할 때 where절에서 or를 사용해 여러개의 id값을 처리한다.
하지만 deleteAllByIdInBatch()의 경우는 where절에서 in을 통해 처리하게 된다.
강의에서도 다뤄주시지 않았고 차이점에 대한 비교 포스팅도 없어서 사실 이 쿼리문에서의 차이 말고는 차이점을 잘 못느끼겠다...
Reference
- 패스트캠퍼스 java/spring 초격차 패키지 Spring Data JPA
- JPQL에서 count 성능 이슈 및 exists 사용
JPQL의 count 성능 이슈 및 exist 사용 방법
Spring의 JPA 사용 중 데이터가 존재하는지 확인하는 방법으로 count 함수를 사용할 때가 있다.단순히 하나의 데이터가 존재하는지 확인하는 경우(아이디 중복확인 등) count 함수를 사용하면 성능상
velog.io
- deleteById와 delete의 차이
Spring Data JPA 사용 시 deleteById 와 delete 의 차이
Spring Data 란? Spring Data’s mission is to provide a familiar and consistent, Spring-based programming model for data access while still retaining the special traits of the underlying data store...
hwanchang.tistory.com
'Spring' 카테고리의 다른 글
| Jpa QueryByExampleExecutor 인터페이스 (0) | 2022.02.08 |
|---|---|
| JPA JpaRepository 메소드 paging (findAll(pageable)) (0) | 2022.02.03 |
| JPA JpaRepository 메소드 (save(), find~()) (0) | 2022.01.28 |
| JPA 기초 (0) | 2022.01.26 |
| JPA란? (0) | 2022.01.13 |