자바에서 함수형 프로그래밍(Functional Programming)을 구현하는 방식이다.
람다식은 클래스를 생성하지 않고 함수의 호출만으로 기능을 수행하며 함수형 인터페이스를 선언한다.
람다는 프로그래밍 언어에서 사용되는 개념으로 익명 함수(Anonymous functions)를 지칭하는 용어다.
현재 사용되고 있는 람다의 근간은 수학과 기초 컴퓨터과학 분야에서의 람다 대수다. 람다대수는 간단히 말하자면
수학에서 사용하는 함수를 보다 단순하게 표현하는 방법이다.
자바 8부터 지원되는 기능이다.
함수형 프로그래밍(Functional Programming)이란?
함수형 프로그램의 특징은 함수 베이스로 프로그래밍을 하는 것이다.
함수 기반의 프로그래밍을 하는데 매개변수를 받아서 그 매개변수를 이용한 프로그래밍을 하게 되면
외부변수들을 사용하지 않는다. 그것을 순수 함수형 프로그래밍이라고 한다.
매개변수만을 사용하도록 만든 함수로 외부자료에 부수적인 영향(Side Effect)가 발생하지 않도록 한다.
함수가 수행됨으로써 다른 변수값이 변한다거나 하는 경우가 발생하지 않기 때문에 병렬처리가 가능하다.
여러가지 효율성이 대두되면서 함수형 프로그래밍 방식이 많이 뜨고 있다고 한다.
특징
익명함수이므로 이름을 가질 필요가 없다.
두개 이상의 입력이 있는 함수는 최종적으로 1개의 입력만 받는 람다 대수로 단순화 될 수 있다.
익명함수(Anonymous Functions)란?
말 그대로 이름이 없는 함수다.
익명함수들은 공통으로 일급객체(First Class citizen)라는 특징을 갖고 있다.
일급 객체란 일반적으로 다른 객체들에 적용 가능한 연산을 모두 지원하는 개체를 가리킨다.
함수를 값으로 사용할 수도 있으며 Parameter로 전달 및 변수에 대입하기와 같은 연산들이 가능하다.
장단점
장점
람다를 사용하면 불필요한 반복문의 삭제가 가능하며 복잡한 식을 단순하게 표현하여 코드량이 줄어든다.
람다는 지연연상을 수행함으로써 불필요한 연산을 최소화한다.
멀티스레드를 활용하여 병렬처리를 사용할 수 있다.
단점
람다는 호출이 까다롭다.
람다 stream 사용 시 단순 for문 혹은 while문 사용 시 성능이 떨어진다.
불필요하게 너무 사용하게 되면 오히려 가독성을 떨어뜨릴 수 있다.
람다식 문법
매개변수가 하나인 경우 괄호 생략이 가능하지만 두개인 경우는 괄호를 생략할 수 없다.
str->{ System.out.println(str); }
중괄호 안의 구현부가 한 문장인 경우는 중괄호를 생략할 수 있다.
str->System.out.println(str);
중괄호 안의 구현부가 한 문장이라도 return 문이라면 중괄호를 생략할 수 없다.
str->return str.length(); //오류발생
중괄호 안의 구현부가 반환문의 하나라면 return 과 중괄호를 모두 생략할 수 있다.
(x, y) -> x + y //두 값을 더하여 반환
str -> str.length(); //문자열 길이를 반환
메서드 선언은 interface를 사용한다.
프로그램내에서 변수는
자료형에 기반하여 선언하고 int a;
매개변수로 전달하고 int add(int x, int y);
메서드의 반환값으로 사용한다. return num;
람다식은 프로그램내에서 변수처럼 사용할 수 있다.
예제코드
//Interface
public interface PrintString {
void show(String str);
}
//Test class
public class TestLambda {
public static void main(String[] args) {
PrintString lambdastr = s-> System.out.println(s);
lambdastr.show("hi");
showMyString(lambdastr);
PrintString test = returnString();
test.show("test");
}
public static void showMyString(PrintString p) {
p.show("Hello");
}
public static PrintString returnString() {
return s-> System.out.println(s + "!!!");
}
}
결과값은
hi Hello test!!!
이렇게 출력된다.
lambdastr.show라는 것은 lambdastr에서 구현되어있는 출력문에 s를 넣어서 넘겨준다는 것인데
결국에는 PrintString.show에 lambdastr이라는 함수가 생겨나면서 그 매개변수로 "hi"가 넘어가고
그럼 함수에 출력문이 구현되어있으니까 출력이 되는 형태다.
showMyString에서는 PrintString으로 받는다. 그럼 PrintString타입인 lambdastr을 매개변수로 넘겨준다면
showMyString에서는 p.show가 바로 위에 있는 코드와 마찬가지로 lambdastr.show("Hello"); 형태로
처리하는 것이다.
returnString의 경우는 함수의 구현부가 마치 변수처럼 returnString으로 반환이 되어 대입이 되고
그 메서드가 호출 될 수 있다.
test.show로 test를 넘겨줬고 returnString에서는 그럼 test를 s로 받아 s + !!! 의 형태인
test!!!를 출력하게 된다.
함수형 인터페이스 @FuntionalInterface
FunctionalInterface는 일반적으로 구현해야할 추상 메서드가 하나만 정의된 인터페이스를 가리킨다.
자바 컴파일러는 이렇게 명시된 함수형 인터페이스에 두개이상의 메서드가 선언되면 오류를 발생시킨다.
@FunctionalInterface
public interface StringConcat {
public void makeString(String s1, String s2);
}
//구현해야할 메서드가 두개이므로 Functional Interface가 아니기 때문에 오류발생
@FunctionalInterface
public interface StringConcat {
public void makeString(String s1, String s2);
public void make(String s1, String s2);
}
예제코드
@FunctionalInterface
public interface MyMaxNumber {
int getMaxNumber(int x, int y);
}
//Test class
public class TestMyMaxNumber {
public static void main(String[] args) {
MyMaxNumber max = (x, y)->(x >= y) ? x : y;
System.out.println(max.getMaxNumber(10, 20));
}
}
20이 결과값으로 출력된다.
x, y 두개의 매개변수가 넘어올건데 인터페이스의 메서드가 호출되면 익명이고 max라는 이름으로 구현된 것은
x와 y 중에 더 큰값을 반환하라고 했다.
반환되는 것이지만 return을 붙이면 중괄호가 있어야 하기 때문에 그냥 사용한 코드다.
만약 return을 붙여준다면
MyMaxNumber max = (x, y)->{return (x >= y) ? x : y; };
이렇게 작성하면 된다.
예제코드2
@FunctinalInterface
public interface StringConcat {
public void makeString(String s1, String s2);
}
//impl class
public class StringConImpl implements StringConcat {
@Override
public void makeString(String s1, String s2) {
System.out.println(s1 + ", " + s2);
}
}
//Test class
public class TestStringConcat {
public static void main(String[] args) {
StringConImpl impl = new StringConImpl();
impl.makeString("hello", "world");
StringConcat concat = (s, v)-> System.out.println(s + ", " + v);
concat.makeString("Hello", "World");
StringConcat concat2 = new StringConcat() {
@Override
public void makeString(String s1, String s2) {
System.out.println(s1 + ", " + s2);
}
};
concat2.makeString("hello, ", "world, ");
}
}
결과값은
hello, world Hello, World hello, , world,
이렇게 출력된다.
제일 처음 StringConImpl을 사용한 방법은 람다를 사용하지 않았을 때 원래 사용하던 인터페이스 방식이다.
concat의 코드를 보면 Impl 클래스를 거치지 않고 인터페이스 타입으로 바로 처리한다.
s와 v로 매개변수를 받고 받아왔다면 출력문에 s , v 형태로 출력하도록 한것이다.
그래서 Hello, World가 출력되게 되는 형태다.
마지막 concat2의 경우는 concat이 처리되는 방법이라고 볼 수 있다.
람다식으로 구현했지만 실행되면서 내부적으로 익명객체가 자동으로 생성되면서 처리되는 것이다.
이렇게 람다식을 사용하면 좀 더 간결한 코드로 처리가 가능하다.
여기까지는 기초적인 사용에 대한 것인것 같고 좀 더 깊이 들어가서 익숙해진다면 오히려 더 편하게 사용할 수 있지
제네릭은 자바 1.5부터 추가된 기능으로 복잡한 애플리케이션을 개발 할 때 발생하는 여러가지 버그들을
많이 줄일 수 있다.
제네릭은 안드로이드와 같은 애플리케이션을 개발할 때 많이 사용되므로 정확하게 알고 있어야 한다.
변수의 선언이나 메소드의 매개변수를 하나의 참조자료형이 아닌 여러 자료형을 변환될 수 있도록
프로그래밍 하는 방식이다.
실제 사용되는 참조 자료형으로의 변환은 컴파일러가 검증하므로 안정적인 프로그래밍 방식이다.
제네릭(Generic)이란?
제네릭은 클래스를 정의할 때 구체적인 타입(type)을 적지 않고 변수형태로 적어놓는 것이다.
클래스를 선언하여 객체를 생성할 때, 구체적인 타입을 기재한다. 즉, 타입을 어떤 클래스 종류의 매개변수로 본다.
타입 매개변수의 표기
제네릭 클래스는 여러개의 타입 매개변수를 가질 수 있으나 타입의 이름은 클래스나 인터페이스 안에서 유일해야 한다
타입의 이름은 대문자로 하는데 변수의 이름과 타입의 이름을 구별할 수 있게 하기 위함이다.
타입 매개변수
E - Element
K - Key
N - Number
T - Type
V - Value
S, U, V 등 - 2번째, 3번째, 4번째 타입
자바 SE 7 버전부터는 제네릭 클래스의 생성자를 호출할 때, 타입 인수를 구체적으로 주지 않아도 된다.
컴파일러가 문맥에서 타입을 추측하기 때문이다.
Box<String> box = new Box<>();
Box<String> box = new Box<String>();
이렇게 굳이 <>안에 구체적으로 적어주지 않아도 사용이 가능하다.
제네릭메서드
일반클래스의 메서드에서도 타입 매개변수를 사용하여 제네릭메서드를 정의할 수 있다.
제네릭 메서드에서의 타입 매개변수의 범위는 메서드 내부로 제한된다.
타입 매개변수(<T>)는 반드시 메서드의 수식자(public, static)와 반환형(T) 사이에 위치되어야 한다.
public static <T> T getMaterial(T[] a)
예제코드
//material class
public abstract class material {
public abstract void doPrinting();
}
//Plastic
public class Plastic extends material {
public String toString() {
return "재료는 Plastic입니다.";
}
@Override
public void doPrinting() {
System.out.println("Plastic으로 프린팅한다.");
}
}
//Powder
public class Powder extends material {
public String toString() {
return "재료는 Powder 입니다.";
}
@Override
public void doPrinting() {
System.out.println("Powder로 프린팅 합니다.");
}
}
//Water
public class Water {
//아무것도 작성하지 않음.
}
//generic class
public class GenericPrinter<T extends material> {
//extends로 T대신 사용될 자료형을 제한
//material에 정의된 메소드를 공유할 수 있다.
//material을 상속받지 않았다면 접근할 수 없다.
private T material;
public T getMeterial() {
return material;
}
public void setMaterial(T material) {
this.material = material;
}
public String toString() {
return material.toString();
}
publid void printing() {
material.doPrinting();
}
}
//Test class
public class GenericPrinterTest {
public static void main(String[] args) {
GenericPrinter<Powder> powderPrinter = new GenericPrinter<Powder>();
Powder powder = new Powder();
powderPrinter.setMaterial(powder);
System.out.println(powderPrinter);
GenericPrinter<Plastic> plasticPrinter = new GenericPrinter<Plastic>();
Plastic plastic = new Plastic();
plasticPrinter.setMaterial(plastic);
System.out.println(plasticPrinter);
powderPrinter.printing();
plasticPrinter.printing();
}
}
get(i)가 제공되지 않아 Iterator로 순회하며 저장된 순서와 출력순서는 다를 수 있다.
아이디, 주민번호, 사번 등 유일한 값이나 객체를 관리할 때 사용한다.
HashSet과 TreeSet클래스가 있다.
Iterator로 순회
Collection의 개체를 순회하는 인터페이스다.
iterator ir = memberArrayList.iterator(0;
이런 형태로 사용한다.
Iterator에 선언된 메서드
메서드
설명
boolean hashNext()
이후에 요소가 더 있는지를 체크하는 메서드이며,
요소가 있다면 true를 반환한다.
E next()
다음에 있는 요소를 반환한다.
HashSet 클래스
Set인터페이스를 구현한 클래스다.
Set은 중복을 허용하지 않고 해시방식으로 데이터를 관리하기 때문에 입력하는 순서와 출력하는 순서는 다르다.
ArrayList로 만들어 출력할때는 중복도 허용하기 때문에 중복값과 입력순서대로 출력이 되지만
HashSet으로 만들어 출력하면 중복데이터는 한번만 출력되고 순서도 입력순서와 다르게 출력된다.
HashSet을 사용할 때는 객체가 논리적으로 같은지에 대한 정의가 되어 있어야 한다.
String으로만 처리한다면 String에는 이미 정의가 되어 있으므로 상관없지만 직접 만든 클래스에 대해서는 정의를
해야 한다.
같은지에 대한 정의는 equals와 hashCode로 한다.
import java.util.*;
public class HashSetTest {
public static void main(String[] args) {
HashSet<String> set = new HashSet<>();
set.add("이순신");
set.add("강감찬");
set.add("김유신");
set.add("이순신");
System.out.println(set);
Iterator<String> ir = set.iterator();
while(ir.hasNext()) {
String str = ir.next();
System.out.println(str);
}
}
}
결과값은 김유신, 강감찬, 이순신 김유신 강감찬 이순신 이렇게 출력된다.
ArrayList로 만들었을 때는 입력한 순서대로 출력이 되고 중복되는 값도 출력이 되었지만 HashSet은
중복도 허용하지 않고 순서도 입력순이 아닌 다른 순서대로 출력된다.
그리고 LinkedList 예제에서처럼 get(i)는 set에서 사용할 수 없다고 했다.
set인터페이스에서는 get(i)를 사용할 수 없기 때문에 Iterator를 이용해서 호출하여 출력한다.
HashSet예제 2
//Member class
public class Member {
private int memberId;
private String memberName;
public Member() { } //default Constructor
public Member(int memberId, String memberName) { //Constructor
this.memberId = memberId;
this.memberName = memberName;
}
//getter, setter
public int getMemberId() {
return memberId;
}
public void setMemberId(int memberId) {
this.memberId = memberId;
}
public String getMemberName() {
return memberName;
}
public void setMemberName() {
this.memberName = memberName;
}
public String toString() {
return memberName + " 회원님의 아이디는 " + memberId + " 입니다.";
}
//equals hashCode
@Override
public boolean equals(Object o) {
if(o instanceof Member) {
Member member = (Member)o;
return (this.memberId == member.memberId);
}
return false;
}
@Override
public int hashCode() {
return memberId;
}
}
//Member HashSet class
import java.util.*;
public class MemberHashSet {
private HashSet<Member> hashSet;
public MemberHashSet() {
hashSet = new HashSet<Member>();
}
public void addMember(Member member) {
hashSet.add(member);
}
public boolean removeMember(int memberId) {
Iterator<Member> ir = hashSet.iterator();
while(ir.hasNext()) {
Member member = ir.next();
if(member.getMemberId() == memberId) {
hashSet.remove(member);
return true;
}
}
System.out.println(memberId + " 번호가 존재하지 않습니다.");
return false;
}
public void showAllMember() {
for(Member member : hashSet) {
System.out.println(member);
}
System.out.println();
}
}
//Test class
public class MemberHashSetTest {
public static void main(String[] args) {
MemberHashSet manager = mew MemberHashSet();
Member memberLee = new Member(100, "Lee");
Member memberKim = new Member(200, "Kim");
Member memberPark = new Member(300, "Park");
Member memberPark2 = new Member(300, "Park2");
manager.addMember(memberLee);
manager.addMember(memberKim);
manager.addMember(memberPark);
manager.addMember(memberPark2);
manager.showAllMember();
}
}
결과값은
Lee 회원님의 아이디는 100입니다.
Kim 회원님의 아이디는 200입니다.
Park 회원님의 아이디는 300입니다.
이렇게 출력된다. Park2의 경우는 아이디가 300으로 Park과 중복되기 때문에 출력되지 않는다.
Member 클래스에서 equals와 hashCode로 아이디값이 동일하다면 논리적으로 같은 값이라고 판단하기 때문이다.
Member 클래스에서 equals와 hashCode를 지우고 실행한다면 Park2역시 출력된다.
String클래스에서는 미리 구현되어 있기 때문에 따로 equals와 hashCode를 구현하지 않아도 되지만
이렇게 직접 만들어준 클래스에 대해서는 꼭 구현을 해줘야 중복값을 처리할 수 있다.
TreeSet 클래스
객체의 정렬에 사용되는 클래스다.
중복을 허용하지 않으면서 오름차순이나 내림차순으로 객체를 정렬한다.
내부적으로 이진검색트리(Binary Search Tree)로 구현되어 있다.
이진검색트리에 자료가 저장될 때 비교하여 저장될 위치를 정한다.
객체의 비교를 위해 Comparable이나 Comparator 인터페이스를 구현해야 한다.
Comparable인터페이스와 Comparator 인터페이스는 정렬대상이 되는 클래스가 구현해야 하는 인터페이스다.
Comparable은 compareTo 메서드를 구현한다.
매개변수와 객체 자신(this)를 비교한다.
Comparator는 compare() 메서드를 구현한다.
두개의 매개변수를 배교하며 TreeSet 생성자에 Comparator가 구현된 객체를 매개변수로 전달한다.
TreeSet<Member> treeSet = new TreeSet<Member>(new Member());
이러한 형태로 사용할 수 있으며 일반적으로는 Comparable을 더 많이 사용한다.
이미 Comparable이 구현된 경우에는 Comparator를 이용하여 다른 정렬방식을 정의할 수 있다.
TreeSet 예제 1
import java.util.*;
class MyCompare implements Comparator<String> {
@Override
putlic int compare(String s1, String s2) {
return s1.compareTo(s2) * (-1);
}
}
public class ComparatorTest {
public static void main(String[] args) {
TreeSet<String> treeSet = new TreeSet<String>();
treeSet.add("홍길동");
treeSet.add("강감찬");
treeSet.add("이순신");
for(String str : treeSet) {
System.out.println(str);
}
}
}
결과값은 강감찬 이순신 홍길동 이렇게 출력된다.
여기서는 String 클래스에 이미 Comparable이 구현되어 있기 때문에 오름차순으로 정렬되어 출력된다.
하지만 내림차순으로 출력하고 싶다면 Comparator를 이용해 정의한 MyCompare를 이용해 정렬하면 된다.
TreeSet<String> treeSet = new TreeSet<String>(new MyCompare());
이렇게 쓰면 되고 생성자에 추가해서 이 방식으로 정렬하라고 하는 것이다.
TreeSet 예제 2
//Member Class
public class Member implements Comparable<Member> {
private int memberId;
private String memberName;
public Member() { }
public Member(int memberId, String memberName) {
this.memberId = memberId;
this.memberName = memberName;
}
public int getMemberId() {
return memberId;
}
public void setMemberId(int memberId) {
this.memberId = memberId;
}
public String getMemberName() {
return memberName;
}
public void setMemberName(String memberName) {
this.memberName = memberName;
}
public String toString() {
return memberName + " 회원님의 아이디는 " + memberId + " 입니다.";
}
//memberId가 같은 경우 두 값은 논리적으로 같은 값이라는 것을
//구현하기 위해 equals와 hashCode를 작성
@Override
public boolean equals(Object o) {
if(o instanceof Member) {
Member member = (Member)o;
return (this.memberId == member.memberId);
}
return false;
}
@Override
public int hashCode() {
return memberId;
}
@Override
public int compareTo(Member o) {
return (this.memberId - o.memberId);
/*
내 값이 더 클때 양수를 반환하게 되면 오름차순으로 정렬하게 된다.
그래서 내림차순으로 정렬하고 싶다면 * (-1)을 추가해서 음수로 반환하게 하면 된다.
이름으로 정렬하고 싶다면
this.memberName.compareTo(member.getMemberName());
이렇게 작성한다.
String은 compareTo가 구현되어 있기 때문에
그냥 사용하면 된다.
그리고 예제1에서와 마찬가지로 String역시 내림차순으로 정렬하고 싶을때는
* (-1)을 추가한다.
*/
}
}
/*
Comparable말고 다른 방법으로는
Comparator가 있다.
implements Comparator<Member>로 작성하면 되고
그럼
@Override
public int compare(Member o1, Membmer o2) {
return (o1.memberId - o2.memberId);
}
이렇게 작성하면 된다.
o1이 this고 o2가 매개변수가 된다.
마찬가지로 이렇게 처리해서 양수가 반환되면 오름차순
* (-1)을 해서 음수를 반환하게 되면 내림차순이 된다.
*/
//MemberTreeSet class
import java.util.*;
public class MemberTreeSet {
private TreeSet<Member> treeSet;
public MemberTreeSet() {
treeSet = new TreeSet<Member>();
/*
만약 Member 클래스에서 Comparable이 아닌
Comparator로 작성했다면
treeSet = new TreeSet<Member>(new Member());
이렇게 작성한다.
*/
}
public void addMember(Member member) {
treeSet.add(member);
}
public boolean removeMember(int memberId) {
Iterator<Member> ir = treeSet.iterator();
while(ir.hasNext()) {
Member member = ir.next();
if(member.getMemberId() == memberId) {
treeSet.remove(member);
return true;
}
}
System.out.println(memberId + " 번호가 존재하지 않습니다.");
return false;
}
public void showAllMember() {
for(Member member : treeSet) {
System.out.println(member);
}
System.out.println();
}
}
//Test class
public class MemberTreeSetTest {
public static void main(String[] args) {
MemberTreeSet manager = new MemberTreeSet();
Member memberLee = new Member(300, "Lee");
Member memberKim = new Member(100, "Kim");
Member memberPark = new Member(200, "Park");
manager.addMember(memberLee);
manager.addMember(memberKim);
manager.addMember(memberPark);
manaber.showAllMember();
}
}
결과값은
Kim회원님의 아이디는 100입니다.
Park회원님의 아이디는 200입니다.
Lee회원님의 아이디는 300입니다.
이렇게 출력된다.
만약 Member클래스에서 Comparable을 implements해주지 않는다면 ClassCastException이 발생한다.
Member cannot be cast to java.lang.Comparable 이라는 오류를 확인할 수 있는데
Comparable을 cast할 수 없다는 것이다.
예제 1에서는 String클래스에 Comparable이 구현되어있었으니 문제가 없었지만 Member클래스에서는 따로
구현하지 않았다면 Comparable을 찾을 수 없기 때문이다.
Map Interface
key-value pair의 객체를 관리하는데 필요한 메서드가 정의된다.
key는 중복될 수 없으며 검색을 위한 자료구조다.
key를 이용하여 값을 저장하거나 검색, 삭제할 때 사용하면 편리하다.
내부적으로 hash방식으로 구현되며 key가 되는 객체는 유일함의 여부를 알기 위해
equals와 hashCode메서드를 재정의한다.
HashMap클래스
Map인터페이스를 구현한 클래스 중 가장 일반적으로 사용하는 클래스다.
HashTable클래스는 자바2부터 제공된 클래스로 Vector처럼 동기화를 제공한다.
pair 자료를 쉽고 빠르게 관리할 수 있다.
HashMap 예제코드
//Member class
public class Member {
private int memberId;
private String memberName;
public Member() { }
public Member(int memberId, String memberName) {
this.memberId = memberId;
this.memberName = memberName;
}
public int getMemberId() {
return memberId;
}
public void setMemberId(int memberId) {
this.memberId = memberId;
}
public String getMemberName() {
return memberName;
}
public void setMemberName(String memberName) {
this.memberName = memberName;
}
public String toString() {
return memberName + " 회원님의 아이디는 " + memberId + " 입니다.";
}
@Override
public boolean equals(Object o) {
if(o instanceof Member) {
Member member = (Member)o;
return (this.memberId == member.memberId);
}
return false;
}
@Override
public int hashCode() {
return memberId;
}
}
//MemberHashMap class
import java.util.*;
public class MemberHashMap {
private HashMap<Integer, Member> hashMap;
public MemberHashMap() {
hashMap = new HashMap<Integer, Member>();
}
public void addMember(Member member) {
hashMap.put(member.getMemberId(), member);
//member.getMemberId가 key
//member가 value가 된다.
}
public boolean removeMember(int memberId) {
if(hashMap.containsKey(memberId)) { //키값에 해당하는 값이 있는지
hashMap.remove(memberId);
return true;
}
System.out.println("회원번호가 없습니다.");
return false;
}
public void showAllMember() {
Iterator<Integer> ir = hashMap.keySet().iterator();
//모든 set 객체를 반환한다.
//key객체를 반환하는데 key는 중복되지 않으므로 set타입으로 반환한다.
while(ir.hasNext()) {
int key = ir.next();
Member member = hashMap.get(key);
System.out.println(member);
}
System.out.println();
}
}
//Test class
public class MemberHashMapTest {
public static void main(String[] args) {
MemberHashMap manager = new MemberHashMap();
Member memberLee = new Member(100, "Lee");
Member memberKim = new Member(200, "Kim");
Member memberPark = new Member(300, "Park");
Member memberPark2 = new Member(300, "Park2");
manager.addmember(memberLee);
manager.addmember(memberKim);
manager.addmember(memberPark);
manager.addmember(memberPark2);
manager.showAllMember();
manager.removeMember(200);
manager.showAllMember();
}
}
키값이 Integer고 Integer에는 equals와 hashCode가 구현되어 있기 때문에 중복값은 출력하지 않는다.
TreeMap 클래스
key 객체를 정렬하여 key-value를 pair로 관리하는 클래스다.
key에 사용되는 클래스에 Comparable, Comparator 인터페이스를 구현한다.
자바에 많은 클래스들은 이미 Comparable이 구현되어 있다.
구현된 클래스를 key로 사용하는 경우에는 구현할 필요가 없다.
TreeMap 예제코드
//Member class
public class Member {
private int memberId;
private String memberName;
public Member() { }
public Member(int memberId, String memberName) {
this.memberId = memberId;
this.memberName = memberName;
}
public int getMemberId() {
return memberId;
}
public void setMemberId(int memberId) {
this.memberId = memberId;
}
public String getMemberName() {
return memberName;
}
public void setMemberName(String memberName) {
this.memberName = memberName;
}
public String toString() {
return memberName + " 회원님의 아이디는 " + memberId + " 입니다.";
}
@Override
public boolean equals(Object o) {
if(o instanceof Member) {
Member member = (Member)o;
return (this.memberId == member.memberId);
}
return false;
}
@Override
public int hashCode() {
return memberId;
}
}
//MemberTreeMap class
import java.util.*;
public class MemberTreeMap {
private TreeMap<Integer, Member> treemap;
public MemberTreeMap() {
treeMap = new TreeMap<Integer, Member>();
}
public void addMember(Member member) {
treeMap.put(member.getMemberId(), member);
}
public boolean removeMember(int memberId) {
if(treeMap.containsKey(memberId)) {
treeMap.remove(memberId);
return true;
}
System.out.println("회원번호가 없습니다.");
return false;
}
public void showAllMember() {
Iterator<Integer> ir = treeMap.keySet().iterator();
while(ir.hasNext()) {
int key = ir.next();
Member member = treeMap.get(key);
System.out.println(member);
}
System.out.println();
}
}
//Test class
public class MemberTreeMapTest {
public static void main(String[] args) {
MemberTreeMap manager = new MemberTreeMap();
Member memberPark = new Member(300, "Park");
Member memberLee = new Member(100, "Lee");
Member memberKim = new Member(200, "Kim");
Member memberPark2 = new Member(300, "Park2");
manager.addMember(memberLee);
manager.addMember(memberKim);
manager.addMember(memberPark);
manager.addMember(memberPark2);
manager.showAllMember();
manager.removeMember(200);
manager.showAllMember();
}
}
이런 불능상태로 들어가기 전에 처리하여 불능상태를 만들지 않기 위해 Exception 예외처리라는 방법을 통해
Exception Error를 처리한다.
예외처리라는것은 Exception 예외가 발생할 것을 대비하여 미리 예측해 이를 소스상에서 제어하고 처리하도록 만드는
것이다. 이렇게 예외처리를 하게 되면 갑작스러운 Exception이 발생해도 시스템 및 프로그램이 불능상태가 되지 않고
정상 실행을 유지할 수 있다.
오류란?
컴파일 오류 : 프로그램 코드 작성 중 발생하는 문법적 오류
실행 오류 : 실행중인 프로그램이 의도하지 않은 동작을 하거나(Bug) 프로그램이 중지되는 오류(Runtime Error)
자바는 예외처리를 통하여 프로그램의 비정상 종료를 막고 log를 남길 수 있다.
오류와 예외클래스
시스템오류(error) : 가상 머신에서 발생하여 프로그래머가 처리할 수 없다.
동적메모리를 다 사용한 경우다 Stack over flow 등
예외(Exception) : 프로그램에서 제어할 수 없는 오류다.
읽으려는 파일이 없는 경우나 네트워크 소켓연결 오류 등이 있다.
자바프로그램에서는 예외에 대한 처리를 수행한다.
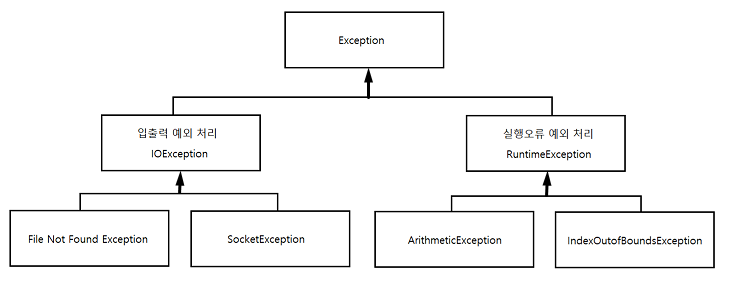
예외클래스
모든 예외클래스의 최상위 클래스는 Exception 클래스다.
예외처리
try-catch 문으로 예외처리하기
try {
//예외가 발생할 수 있는 코드
}catch(처리할 예외타입 e) {
//try블록 안에서 예외가 발생했을 때 수행되는 코드
}
예제코드
//try catch
public class ArrayExceptionTest {
int[] arr = new int[5];
try {
for(int i = 0; i <= 5; i++) {
System.out.println(arr[i]);
}
}catch(ArrayIndexOutofBoundsException e) {
System.out.println(e);
System.out.println("예외처리 중");
}
System.out.println("프로그램 종료");
}
/*
반복문을 try안에 넣지 않고 돌리면
OutOfBoundsException 이 발생한다.
배열은 5의 크기를 갖고 있는데
반복문은 0에서 5까지 반복시키니까 마지막
arr[5]가 없기 때문에 발생.
*/
try-catch-finally 문으로 예외처리하기
try {
//예외발생 코드
}catch(처리할 예외타입 e) {
//try블록 안에서 예외가 발생했을 때 수행되는 코드
}finally {
//예외발생 여부와 상관없이 항상 수행되는 코드
//리소스 해제하는 코드를 주로 사용
}
예제코드
/*
프로젝트내에 a.txt를 만들고 코드 실행
try-catch-finally
*/
public class ExceptionTest {
public static void main(String[] args) {
FileInputStream fis = null;
try {
fis = new FileInputStream("a.txt");
}catch(FileNotFoundException e) {
System.out.println(e);
return;
}finally {
try {
fis.close();
System.out.println("finally");
}catch(Exception e) {
System.out.println(e);
}
}
System.out.println("end");
}
}
FileInputStream 은 close로 닫아줘야 한다. 첫 try문 안에서 닫아줘도 되지만 오류가 발생한다면
close에 도달하지 못하기 때문에 finally에서 처리하도록 해 Exception이 발생하던 안하던 처리하도록 해준다.
그리고 finally 내부에서 close를 실행했지만 코드에서 fis가 null이기 때문에 finally는 출력하지 않고
catch에서 예외처리를 한다.
그리고 만약 a.tx파일을 만들지 않고 실행하게 된다면 첫 catch에서 return을 하기 때문에 end 역시 출력되지
않는다.
try-with-resources
리소스를 자동으로 해제하도록 제공해주는 구문이다.
해당 리소스가 AutoCloseable을 구현한 경우 close()를 명시적으로 호출하지 않아도 try블록에서 오픈된 리소스는
정상적인 경우나 예외가 발생한 경우 모두 자동으로 close()가 호출된다.
자바 7부터 제공이 되며 FileInputStream의 경우는 AutoCloseable을 구현하고 있다.
예제코드
//try-with-resources 방식
public class ResouceExceptionTest {
public static void main(String[] args) {
try(FileInputStream fis = new FileInputStream("a.txt")) {
}catch(FileNotFoundException e) {
System.out.println(e);
}catch(IOException e) {
System.out.println(e);
}
System.out.println("end");
}
}
이러한 형태로 사용하고 IOException은 AutoCloseable이 수행되지 않았을 경우가 있을 수 있기 때문에
IOException으로 처리하도록 한다.
예제코드2
//AutoClose가 어떻게 처리되는지를 확인하기 위한 예제
//AutoCloseable
public class AutoCloseObj implements AutoCloseable {
@Override
public void close() throws Exception {
System.out.println("close 호출");
}
}
//Test Class
public class CloseAutoTest {
public static void main(String[] args) {
try(AutoCloseObj obj = new AutoCloseObj()) {
throw new Exception();
}catch(Exception e) {
System.out.println(e);
}
}
}
결과값으로 close 호출 java.lang.Exception 이 출력되는 것을 확인할 수 있다.
메서드를 호출할 때 생성되거나, 인터페이스 타입 변수에 대입할 때 new 예약어를 사용하여 생성
예제코드
class OutClass {
private int num = 10;
private static int sNum = 20;
private InClass inClass;
public OutClass() {
inClass = new InClass();
} //Constructor End
//innerClass를 주로 OutClass의 Constructor에서 많이 생성한다.
class InClass() {
int iNum = 100;
void inTest() {
System.out.println(num);
System.out.println(sNum);
}
} //InClass End
/*
InnerClass다. 메서드 안에 있는 것도 아니고
static이 붙은것도 아니기 때문에 instance Inner Class다.
안에 있는 변수인 iNum의 경우는 static를 붙이면 에러가 발생한다.
InnerClass는 생성이후에 쓸 수 있는 클래스인데
static은 생성과 관계없이 쓸 수 있기 때문에 오류가 발생한다.
물론 클래스에도 static을 붙인다면 문제가 되지 않지만
현재는 Instance Inner Class 이고 OutClass 이후에 생성되야 하기
때문에 사용할 수 없다.
*/
public void usingInner() {
inClass.inTest();
}
static class InStaticClass {
//static Inner Class이며 OutClass의 생성 여부와 상관없이 사용된다.
int inNum = 100;
static int sInNum = 200;
void inTest() {
System.out.println(inNum);
System.out.println(sInNum);
System.out.println(sNum);
}
static void sTest() {
System.out.println(sInNum);
System.out.println(sNum);
}
/*
static 클래스이기 때문에 static 변수나 static 메서드를 만들 수 있다.
여기서 static이 아닌 inNum은 사용할 수 없다.
inNum의 경우는 static 메서드들 보다 나중에 생성되기 때문이다.
*/
} //InStaticClass End
} //OutClass End
public class InnerTest {
public static void main(String[] args) {
OutClass outClass = new OutClass();
outClass.usingInner();
//InClass를 private변수로 만들었기 때문에 부를 수 없다.
//그래서 usingInner를 만들어서 호출한다.
OutClass.InClass myInClass = outClass.new InClass();
//많이 쓰는 문법은 아니라고 한다.
//outClass에서만 쓰려고 InnerClass를 사용하는 것인데
//이렇게 사용할거면 InnerClass로 만들어줄 필요가 없기 때문이다.
//문법적으로는 사용이 가능하다는 것이고
//이렇게 사용하는것도 방지하고자 한다면 InClass를 Private 으로 만들어주면 된다.
System.out.println();
OutClass.InStaticClass.sTest();
/*
static메서드는 이렇게 호출해서 사용할 수 있다.
하지만 inTest메서드는 static 메서드가 아니기 때문에
이렇게 호출 할 수는 없다.
inTest 메서드는
OutClass.InStaticClass.sInClass = new OutClass.InStaticClass();
sInClass.inTest();
이렇게만 호출이 가능하다.
sTest()도 이렇게 호출할 수 있다.
*/
}
} //InnerTest End
//지역 내부 클래스
class Outer {
int outNum = 100;
static int sNum = 200;
Runnable getRunnable(int i) {
int num = 100;
class MyRunnable implements Runnable {
@Override
public void run() {
//이렇게 메서드 안에 클래스를 만들면
//지역 내부 클래스이다.
System.out.println(num);
System.out.println(i);
System.out.println(outNum);
System.out.println(Outer.sNum);
/*
여기서 num과 i는 메서드 안에 있는 지역변수다.
이 메서드가 호출되서 끝날때까지만 유효한게
지역변수이지만 MyRunnable이 반환되고 나면
이 메서드가 끝난 다음에도 run은 언제든지
호출 될 수 있다.
그럼 이 run이 호출되었을 때는 지역변수이기 때문에
변수가 유효하지 않게 된다.
그래서 지역내부 클래스가 쓰이는 메서드에서 변수들은
상수가 된다.
*/
} //run method End
}//MyRunnable End
return new MyRunnable();
} //getRunnable End
} //Outer End
public class LocalInnerClassTest {
public static void main(String[] args) {
Outer outer = new Outer();
Runnable runnable = outer.getRunnable(50);
runnalbe.run();
}
} //Test End
//익명 이너 클래스
class Outer {
int outNum = 100;
static int sNum = 200;
Runnable getRunnable(int i) {
int num = 100;
return new Runnable() {
@Override
public void run() {
Sytem.out.println(num);
Sytem.out.println(i);
Sytem.out.println(outNum);
Sytem.out.println(sNum);
}
};
//익명 이너클래스다. 이름이 없는 이너클래스.
}
Runnable runner = new Runnable() {
@Override
public void run() {
System.out.println("test");
}
};
/*
이렇게도 작성할 수 있다.
익명 이너 클래스는 바로 인터페이스나 추상클래스에 대한 생성을
바로 할 수 있다.
원래는 상속받은 클래스를 만들도 클래스를 생성해서 사용했는데
단 하나의 인터페이스나 단 하나의 추상클래스인 경우는
클래스의 이름없이 new 키워드를 이용해 생성할 수 있다.
*/
} //Outer End
public class AnonymousInnerClassTest {
public static void main(String[] args) {
Outer outer = new Outer();
outer.runner.run();
Runnable runnable = outer.getRunnable(50);
runnable.run();
}
} //Test End
사용하는 경우는 리플렉션 프로그래밍(Reflection Programming)이나 로컬에 자료형이 없는 경우에 사용한다.
가장 많이 사용하는 경우는 동적로딩할 때다.
//Class 클래스 가져오기
String s = new String();
Class c = s.getClass();
//Object 메서드를 이용한 Class 클래스 호출
Class c = String.Class;
//컴파일 된 상태로 String.Class호출
Class c = Class.forName("java.lang.String"); //동적로딩
//이런 형태로 많이 사용한다.
forName 메서드와 동적로딩은 가장 많이 사용하는 메서드로 Statement가 수행될 때 로딩한다.
컴파일이 아닌 Run 타임에 수행하며 풀네임에 해당하는 클래스가 로컬에 있을 경우 사용이 가능하다.
상황에 맞게 원하는 라이브러리 클래스를 매칭할 수 있다.
컴파일 시 데이터 타입이 모두 binding되어 자료형이 로딩되는것(static Loading)이 아닌 실행 중에 데이터 타입을 알고
binding 되는 방식이다.
JDBC를 사용할 때 JDBC DB 라이브러리(Oracle, MSSQL, MySQL) 모두 Static하게 링크하여 컴파일을 하는 방식이 아닌
해당 라이브러리를 설치한 상태에서 필요할 때 호출 할 수 있도록 동적 로딩을 사용한다.
리플렉션 프로그래밍(Reflection Programming)
Class 클래스로부터 객체의 정보를 가져와 프로그래밍 하는 방식이다.
로컬에 객체가 없고 자료형을 알 수 없는 경우 유용한 프로그래밍이다.
java.lang.reflect 패키지에 있는 클래스를 활용한다.
예제코드
import java.lang.reflect.Constructor;
import java.lang.reflect.Method;
public class StringClassTest {
public static void main(String[] args) throws ClassNotFoundException {
Class c1 = String.class;
String str = new String();
Class c2 = str.getClass();
Class c3 = Class.forName("java.lang.String");//동적로딩
Constructor[] cons = c3.getConstructors();
for(Constructor con : cons) {
System.out.println(con);
}
System.out.println("----------------------------------------------------------");
Method[] methods = c3.getMethods();
for(Method method : methods) {
System.out.println(method);
}
}
}
실행하면 결과값으로 String의 생성자와 메서드 목록을 볼 수 있다.
반복문을 사용해 모든 목록을 출력하도록 했지만
이 방법은 데이터 타입에 대한 정보를 전혀 모를때 이렇게 사용하면 된다.
위 예제에서처럼 String에 대해 보고 싶다면
String str = new String();
str.
이렇게 하면 보통 IDE에서 사용할 수 있는 생성자목록을 출력해주기 때문에
이런 경우는 굳이 사용할 필요가 없긴 하다.
new Instance() 메서드
Class 클래스 메서드다. new 키워드를 사용하지 않고 인스턴스를 생성할 수 있다.
예제코드
//Person
public class Person {
private String name;
private int age;
public Person() { }
public Person(String name) {
this.name = name;
}
public Person(String name, int age) {
this.name = name;
this.age = age;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public int getAge() {
return age;
}
public void setAge(int age) {
this.age = age;
}
@Override
public String toString() {
return name;
}
}//Person End
//Test
import java.lang.reflect.Constructor;
import java.lang.reflect.InvocationTargetException;
public class ClassTest {
public static void main(String[] args)
throws ClassNotFoundException, IllegalAccessException, InstantiationException,
NoSuchMethodException, InvocationTargetException {
Person person = new Person("James");
System.out.println(person);
Class c1 = Class.forName("classEx.Person");//Person 클래스의 src아래 경로.
Person person1 = (Person)c1.newInstance(); //new Instance는 default Constructor를 호출
System.out.println(person1);
Class[] parameterType = {String.class};
Constructor cons = c1.getConstructor(parameterType);
Object[] initargs = {"Tom"};
Person personT = (Person)cons.newInstance(initargs);
System.out.println(personT);
}
}
모든 클래스는 Object 클래스의 메서드를 사용할 수 있으며 일부 메서드를 재정의하여 사용할 수 있다.
단, 당연히 final 메서드는 재정의할 수 없다.
Object 클래스는 직접 코딩하지 않아도 컴파일러가 import 해주기 때문에 따로 import하지 않아도 사용할 수 있다.
Object 클래스는 주로 toString(), equals(), hashCode(), clone() 을 흔히 재정의해서 사용한다.
toString()
toString 메서드의 원형은
getClass().getName() + "@" + Integer.toHexString(hashCode()); 이렇게 되어있다.
기본 동작은 객체의 해시코드를 출력하게 되며 재정의 하는 목적은 객체의 정보를 문자열 형태로 표현하고 할 때
사용하기 위함이다.
예제코드
class Book {
String title;
String author;
public Book(String title, String author) {
this.title = title;
this.author = author;
}
public String toString(){
return title + ", " + author;
}
}
public class ToStringTest {
public static void main(String[] args) {
Book book = new Book("Java", "name");
System.out.println(book);
String str = new String("Java");
System.out.println(str);
}
}
이 코드를 실행하면 결과는 Java, name Java가 출력된다. 만약 Book 클래스에서 toString을 재정의 하지 않았다면
메모리 주소값을 출력하고 str인 Java를 출력한다.
str의 경우 String 클래스 안에 toString이 이미 정의되어 있기 때문에 문자열이 그대로 출력되지만 Book에서는
toString을 정의하지 않은 상태이기 때문에 메모리주소값이 출력되는 것이다.
이것으로 인해 toString의 원형은 메모리주소라는 것을 확인할 수 있다.
equals()
두 객체의 동일함을 논리적으로 재정의 할 수 있다.
물리적 동일함은 같은 주소를 갖는 객체이고 논리적 동일함은 같은 학번의 학생, 같은 주문번호의 주문과 같은
것이다.
물리적으로 다른 메모리에 위치한 객체라도 논리적으로 동일함을 구현하기 위해 사용하는 메서드다.
예제코드
class Student {
int studentNum;
String name;
public Student(int studentNum, String name) {
this.studentNum = studentNum;
this.name = name;
}
public boolean equals(Object o) {
if(o instanceof Student) {
Student std = (Student)o;
if(this.studentNum == std.studentNum)
return true;
else
return false;
}
return false;
}
}
public class EqualsTest {
public static void main(String[] args) {
String str1 = new String("abc");
String str2 = new String("abc");
System.out.println(str1 == str2);
System.out.println(str1.equals(str2));
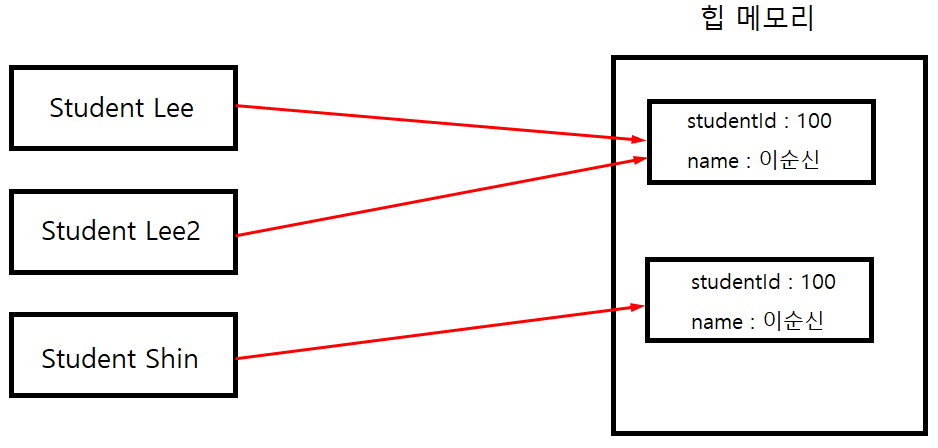
Student Lee = new Student(100, "이순신");
Student Lee2 = Lee;
Student Shin = new Student(100, "이순신");
System.out.println(Lee = Lee2);
System.out.println(Lee = Shin);
System.out.println(Lee.equals(Shin));
}
}
결과값은 false true true false true 가 출력된다.
str1 과 str2 부터 보자면 둘다 abc라는 동일한 값을 갖고 있다.
하지만 str1과 str2의 메모리주소값은 다르기 때문에 같지 않다고 판단하여 false를 반환한다.
두번째 출력문에서는 true가 출력되는데 equals에서 str1과 str2의 문자열이 같은지를 비교했기 때문에
문자열이 같은지 확인하고 true를 반환한 것이다.
아래 출력문을 보자면 Lee와 Shin은 모두 100번의 이순신이라는 이름을 갖고 있다.
그리고 Lee2는 Lee를 갖고 있는데 그렇기 때문에 첫 출력문인 Lee == Lee2는 true가 출력된다.
Lee2가 Lee를 그대로 포함하고 있기 때문에 같다고 판단하게 되고 두번째 출력문에서는 Lee와 Shin을 비교하지만
둘의 메모리주소가 다르기 때문에 false를 출력하게 된다.
그래서 역시 equals를 이용해 논리적으로 true를 넘겨줘서 같은 값이라고 처리할 수 있는 것이다.
이러한 형태가 되기 때문이다. Lee2는 Lee를 그대로 참조하는 것이므로 같은 메모리주소를 갖게 되는것이고
Shin의 경우는 새로 만들어졌으니 다른 메모리주소를 갖게 된다.
이렇게 물리적으로 다른 위치에 있지만 논리적으로 같은 학생임을 구현하는 부분이 equals() 메서드다.
hashCode()
hashCode메서드의 반환값은 인스턴스가 저장된 가상머신의 주소를 10진수로 반환한다.
두개의 서로 다른 메모리에 위치한 인스턴스가 동일하다는 것은
equals의 반환값을 true로 받은 논리적으로 동일한 값이라는 것이다.
동일한 hashCode값을 갖는다는 것은 hashCode의 반환값이 동일하다는 것이다.
메모리 주소값의 10진수로 된 코드가 해시코드이며 16진수로 나온 메모리주소에 .hashCode() 를 붙여주면
10진수형태로 출력된다.
두개의 서로 다른 메모리에 위치한 인스턴스가 동일하다는 것은 equals의 반환값이 true이면서
같은 hashCode를 가져야 동일하다고 보는 것이기 때문에 보통 equals를 재정의할 때 hashCode도 재정의한다.
예제코드
class Student {
int studentNum;
String name;
public Student(int studentNum, String name) {
this.studentNum = studentNum;
this.name = name;
}
@Override
public boolean equals(Object o) {
if(o instanceof Student) {
Student std = (Student)o;
if(this.studentNum == std.studentNum)
return true;
else
return false;
}
return false;
}
@Override
public int hashCode() {
return studentNum;
}
}
public class EqualsTest {
public static void main(String[] args) {
Student Lee = new Student(100, "이순신");
Student Lee2 = Lee;
Student Shin = new Student(100, "이순신");
System.out.println(Lee.hashCode());
System.out.println(Shin.hashCode());
System.out.println(System.identityHashCode(Lee));
System.out.println(System.identityHashCode(Shin));
}
}
hashCode를 재정의하면서 studentNum을 반환하도록 했기 때문에 Lee와 Shin은 같은 100이 출력된다.
그리고 실제 해시코드의 값을 보려 한다면 System.identityHashCode( ) 를 사용하면 된다.
두개의 서로 다른 메모리에 위치한 인스턴스가 동일하다는 것은 equals의 반환값이 true이면서 hashCode가 같아야
하기 때문에 equals와 hashCode를 같이 재정의 한다고 했다.
해시코드를 따로 재정의 하기 전에 실행해보면 Lee의 해시코드와 Shin의 해시코드가 다른것을 확인할 수 있다.
이것을 동일한 인스턴스라는 것을 확인하기 위해 위 코드에서는 equals메서드안에서 studentNum 으로 확인을 했기
때문에 hashCode() 메서드에서도 같은 값을 갖도록 하기 위해 studentNum을 반환해주는것이다.
그럼 equals() 메서드에서도 true를 반환해주었고 hashCode() 메서드에서도 같은 100을 반환해주었기 때문에
둘은 동일한 인스턴스라고 볼 수 있게 되는 것이다.
clone()
clone()메서드는 객체의 복사본을 만든다.
기본틀(prototype)으로부터 같은 속성 값을 가진 객체의 복사본을 생성할 수 있다.
객체지향 프로그래밍의 정보 은닉을 위배할 가능성이 있으므로 복제할 객체는 cloneable 인터페이스를 명시해야 한다.
예제코드
class Book inmplements Cloneable {
String title;
String author;
public Book(String title, String author) {
this.title = title;
this.author = author;
}
@Override
public String toString() {
return title + ", " + author;
}
@Override
protected Object clone() throws CloneNotSupportedException {
return super.clone();
}
}
public class CloneTest {
public static void main(String[] args) throws CloneNotSupportedException {
Book book = new Book("Java", "name");
Book book2 = (Book)book.clone();
System.out.println(book2);
}
}
결과값으로는 Java, name이 출력된다.
clone() 메서드는 특별히 구현하지 않는다.
그리고 clone() 메서드의 원형이 Object로 반환되기 때문에 (Book)이라고 명시적으로 캐스팅 해줘야 한다.
Book클래스에서 Cloneable을 implements하지 않으면 CloneNotSupportedException이 발생한다.
Book 클래스는 복제가 가능하지 않은 클래스인데 복제하려 했기 때문에 오류가 발생했다는 것이다.