QueryMethod는 메소드의 이름을 분석해서 JPQL 쿼리를 실행한다.
사용하기 위해서는 JpaRepository를 상속받아야 한다.
일단 테스트 환경은 다음과 같다.
- Intelli J
- SpringBoot 2.6.2
- Lombok
- Gradle 7.3.2
이전 포스팅인 JpaRepository를 뜯어보면서 거기서 지원해주는 findById, findAll 등등 조회를 도와주는 메소드들을 확인했었다.
근데 대부분 메소드들이 Id를 인자로 받아 처리하는 메소드가 많았는데 사실상 개발하다보면 Id가 아닌 다른 필드로 where절을 구성하는 경우도 많다.
물론 @Query 어노테이션으로 쿼리를 직접 작성하는 방법도 있지만 간단한 쿼리를 편하게 사용할 수 있는 쿼리메소드를 먼저 정리한다.
쿼리메소드는 특정 키워드가 존재한다.
이 키워드들은 Jpa Document에서 확인할 수 있고 목록 하단 Appendix C: Repository query keywords 아래에
Supported query method subject keywords에서 확인할 수 있다.
Spring Data JPA - Reference Documentation
Example 109. Using @Transactional at query methods @Transactional(readOnly = true) interface UserRepository extends JpaRepository { List findByLastname(String lastname); @Modifying @Transactional @Query("delete from User u where u.active = false") void del
docs.spring.io

Description을 보면 Can be used as findBy..., findMyDomainTypeBy... or in combination with additional keywords.
라는 문장을 볼 수 있는데 ...부분에 도메인타입을 넣어주면 된다는것이다.
User에 대한 데이터 조회를 한다고 하면 findUserBy~~~ 이런 형태로.
하지만 생략도 가능하다.
그리고 보통 이미 상속받는 JpaRepository에 타입을 명시하기 때문에 findBy~~~ 형태로 단축해서 많이 사용한다고 한다.
테스트는 아래와 같이 진행했다.
@Data
@NoArgsConstructor
@AllArgsConstructor
@RequiredArgsConstructor
@Entity
public class User{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NonNull
private String name;
@NonNull
private String email;
}public interface UserRepository extends JpaRepository<User, Long>{
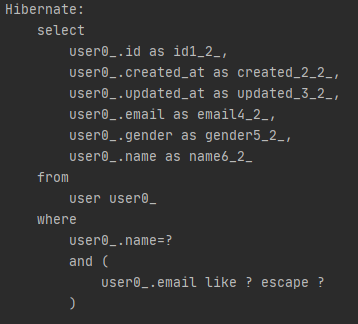
User findByName(String name);
}@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void select(){
System.out.println(userRepository.findByName("coco"));
}이렇게 테스트를 실행하게 되면 정상적으로 coco라는 이름을 갖고 있는 데이터를 조회해 출력해준다.
단, 이렇게 테스트를 실행했는데 만약 coco라는 이름을 갖고 있는 데이터가 복수로 존재한다면
IncorrectResultSizeDataAccessException이 발생한다.
UserRepository에서 findByName은 User 단일 객체 타입인데 여러개의 객체가 조회되기 때문에 발생하는 에러다.
이런 경우 Repository에서 타입을 List타입으로 변경해주면 된다.
public interface UserRepository extends JpaRepository<User, Long>{
List<User> findByName(String name);
}
복수의 데이터를 가져오기 위해서는 무조건 List만 써야하는것은 아니고 Set도 가능하다.
그리고 JpaRepository안에 있는 메소드들 처럼 Optional 타입도 가능하다.
이렇게 리턴 타입에 대해서도 JpaDocument에 나와있다.
Spring Data JPA - Reference Documentation
Example 109. Using @Transactional at query methods @Transactional(readOnly = true) interface UserRepository extends JpaRepository { List findByLastname(String lastname); @Modifying @Transactional @Query("delete from User u where u.active = false") void del
docs.spring.io
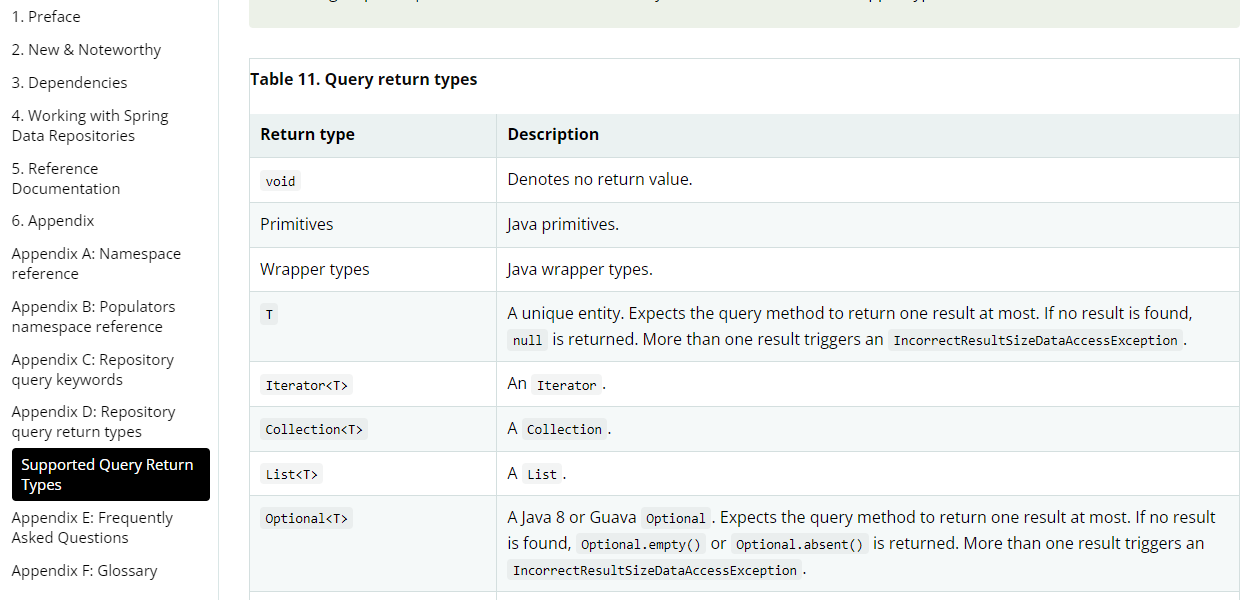
이렇게 여러 리턴 타입을 사용한다는 것은 개발자가 리턴되는 레코드의 수를 예측해 미리 타입을 정의해야 한다고 볼 수 있다.
Query method subject keywords를 보면 find...By, read...By, get...By, query...By, search...By, stream...By가 묶여있는것을 볼 수 있다.
그래서 테스트를 한번 실행.
public interface UserRepository extends JpaRepository<User, Long>{
User findByName(String name);
User getByName(String name);
User readByName(String name);
User queryByName(String name);
User searchByName(String name);
User streamByName(String name);
User findUserByName(String name);
User findSomethingByName(String name);
}@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void select(){
System.out.println("findByName : " + userRepository.findByName("coco"));
System.out.println("getByName : " + userRepository.getByName("coco"));
System.out.println("readByName : " + userRepository.readByName("coco"));
System.out.println("queryByName : " + userRepository.queryByName("coco"));
System.out.println("searchByName : " + userRepository.searchByName("coco"));
System.out.println("streamByName : " + userRepository.streamByName("coco"));
System.out.println("findUserByName : " + userRepository.findUserByName("coco"));
System.out.println("findSomethingByName : " + userRepository.findSomethingByName("coco"));
}이 테스트를 실행하면 모두 동일한 결과를 출력한다.
그럼 결국 묶여있는 모든 키워드가 동일하게 사용된다고 볼 수 있고 강의에서는 가독성을 생각해 편한것으로 작성하면 된다고 한다.
그리고 마지막 두줄의 테스트는 Entity 타입을 인식하는지를 볼 수 있는 테스트다.
findUserByName이나 findSomethigByName이나 둘다 동일한 결과를 리턴하는데 그말은 결국 키워드의 ... 부분에는
존재하는 제대로 된 Entity 타입을 넣어야 하는것이 아닌 단지 가독성을 위한 것이고 인식하는 것은 맨 앞 find 와 by 두 키워드를 인식하고 그 뒤의 필드명을 통해 처리한다고 볼 수 있다.
그리고 생각보다 자주 발생하는 오류라고 나왔던 문제점 하나.
public interface UserRepository extends JpaRepository<User, Long>{
User findByByName(String name);
}@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void select(){
System.out.println("findByByName : " + userRepository.findByByName("coco"));
}이렇게 ByBy 형태로 두번 들어가게 되면 오류가 발생한다.
find 와 By를 인식하기 때문에 ByBy의 경우 둘 다 인식하는듯 하다.
테스트를 실행해보면 BeanCreationException이 발생하고 쭉 옆으로 넘겨서 보면
QueryCreationException: Could not create query for public abstract ...... UserRepository.findByByName(java.lang.String)! Reason: Failed to create query for .......
이런 부분을 볼 수 있는데 query를 만드는 과정에서 발생한 Exception이며 findByByName 쿼리를 생성할 수 없다는 것이다.
Jpa에서는 키워드를 통해 쿼리문을 생성하는데 등록되지 않은 키워드인 find ByBy가 나오니 오류가 발생하는것이다.
다음은 exists...By와 count...By다.
이전 Repository 내의 메소드와 동일하다고 볼 수 있다.
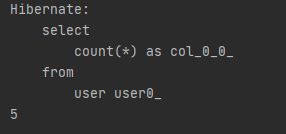
exists...By는 존재여부, count...By는 개수를 출력해준다.
public interface UserRepository extends JpaRepository<User, Long>{
Boolean existsByName(String name);
int countByName(Stirng name);
}@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void select(){
System.out.println("existsByName : " + userRepository.existsByName("coco"));
System.out.println("countByName : " + userRepository.countByName("coco"));
}exists By는 boolean타입으로 리턴하고 count는 숫자 결과를 리턴한다.
그래서 결과는 존재하는 데이터를 조회했다면 true와 그 개수를 출력해준다.
delete는 아래와 같이 사용한다.
public interface UserRepository extends JpaRepository<User, Long>{
int deleteByName(String name);
}@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
@Transactional
void select(){
userRepository.findAll().forEach(System.out::println);
System.out.println(userRepository.deleteByName("coco"));
userRepository.findAll().forEach(System.out::println);
}키워드에서 오는 의미 그대로 삭제해주는 쿼리메소드다. Jpa document에서 보면 remove와 묶여있는데 동일하게 사용되기 때문에 delete만 작성.
결과는 모든 객체를 출력해준 뒤 coco라는 이름을 갖고 있는 데이터 개수를 출력해주고 해당 데이터가 삭제 된 뒤 남은 데이터들을 출력해준다.

JpaDocument에서 키워드를 보면 결과가 없거나 삭제 개수를 리턴한다고 되어 있다.
그래서 deleteByName을 출력하도록 하면 삭제될 데이터 개수가 출력되는 것이다.
그렇기 때문에 Repository에서 타입을 void나 int로 처리해주면 된다.
당연히 void로 하면 출력하도록 할 수 없다.
만약 Entity 타입을 그대로 사용하게 되면 ClassCastException이 발생한다.
그리고 중요한점.
기존 포스팅에서도 그렇고 대체적으로 테스트코드에서 @Transactional 어노테이션을 거의 사용하지 않았는데
deleteBy를 사용하려면 꼭 붙여줘야 한다.
붙이지 않으면 TransactionRequiredException이 발생한다.
근데 deleteBy는 잘 안쓰고 JpaRepository에 있는 delete 메소드로 많이 사용한다고 한다.
다음은 First와 Top이다.
Document의 Description에서 볼 수 있듯이 결과를 첫번째 데이터만 리턴한다.
테스트를 위해 5개의 데이터의 Name을 coco로 통일했다.
public interface UserRepository extends JpaRepository<User, Long>{
User findTop1ByName(String name);
List<user> findFirst2ByName(String name);
}@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
@Transactional
void select(){
System.out.println("findTop1ByName : " + userRepository.findTop1ByName("coco"));
System.out.println("findFirst2ByName : " + userRepository.findFirst2ByName("coco"));
}이렇게 실행하면 top1에서는 id가 1인 데이터 하나만 출력하고 first2에서는 id가 1, 2 인 두개의 데이터만 출력한다.
repository에서는 Top은 User타입으로 first는 List 타입으로 받았는데 둘다 상관없다.
물론 first2ByName처럼 복수의 데이터가 리턴되어야 하는데 단일 객체 타입으로 받으면 오류가 발생한다.
Jpa Document에서는 First<number>, Top<number> 로 나타나있는데 메소드에 그냥 위 처럼 사용해주면 된다.
숫자만 붙여주면 된다.
그리고 이 두 쿼리 메소드의 쿼리를 확인해보면 limit를 통해 가져오는것을 볼 수 있다.
강의에서 first나 top이 있으니 last도 사용할 수 있지 않을까요? 했는데 findLast1ByName을 하게 되면
findByName과 동일한 결과가 출력된다.
즉, 정의되어있지 않은 키워드라는 의미다.
이 쿼리메소드들은 and, or 등 조건을 추가할 수 있는데 그건 다음 포스팅에서............................................................
Reference
- 패스트캠퍼스 java/spring 초격차 패키지 Spring Data JPA
'Spring' 카테고리의 다른 글
| JPA Enum 적용 (0) | 2022.02.19 |
|---|---|
| JPA QueryMethod 2 (where 절 조건 추가) (0) | 2022.02.17 |
| Jpa QueryByExampleExecutor 인터페이스 (0) | 2022.02.08 |
| JPA JpaRepository 메소드 paging (findAll(pageable)) (0) | 2022.02.03 |
| JPA JpaRepository 메소드 (count(), existsById~(), delete~()) (0) | 2022.01.31 |