JPA 연관관계 정리중에 @OneToMany에서 멘붕왔다...
fetchType부터 시작해서 mappedBy까지....
fetchType은 아직도 찾는중이라 mappedBy 먼저 포스팅.
mappedBy에 대해 찾아보다보면 양방향 연관관계가 꼭 따라온다.
연관관계 정리해서 포스팅 해야되니까 여기서는 그냥 간단하게만.......
연관관계는 단방향, 양방향이 존재한다.
제일 많이 나오는 예로 팀과 멤버가 있다.
하나의 팀이 있다면 그 안에는 여러 멤버들이 존재한다.
그렇다면 팀은 1이 되고 멤버들은 N이 된다.
팀은 하나지만 그 안에 속한 멤버는 여러명이기 때문이다.
그래서 이런 관계를 다대일, N:1, 일대다, 1:N 이라고 한다.
보통 데이터베이스 기준에서 보면 N에 외래키를 두게 된다.
매핑은 다대일 먼저 설명.
@Entity
public class User {
...
@ManyToOne
@JoinColumn(name = "tean_id")
private Team team;
...
}
@Entity
public class Team {
...
@Id
@GenerataionValue
@Column(name = "team_id")
private Long no;
...
}다대일 매핑은 이렇게 @ManyToOne을 사용해 처리해준다.
그럼 User가 '다'에 속하기 때문에 User 안에 team의 id값이 존재해야 한다.
이 엔티티들을 erd로 보면 아래와 같다.

코드에서 보면 ManyToOne으로 매핑을 해주겠다고 선언을 하고 JoinColumn 어노테이션을 통해 매핑할 엔티티의 Id 컬럼을 명시한다.
그럼 이제 멤버를 조회할때 어느 팀에 속해있는지 찾을 수 있게 된다.
이렇게 매핑된 상태를 단방향 연관관계라고 한다.
단방향 연관관계는 이렇게 한 방향으로만 참조할 수 있다.
멤버를 통해 소속 팀을 조회할 수 있지만 팀을 조회했을때는 멤버정보를 알 수 없다.
그럼 팀내에 속한 선수들의 목록을 보려면 다시 단방향 매핑으로 연결을 더 해야되나???
이걸 양방향으로 만들어주게 되면 팀에서도 멤버를 조회할 수 있게 된다.
근데 말이 양방향이지 두개의 단방향 연관관계가 묶여있다고 볼 수 있다.
@Entity
public class User {
...
@ManyToOne
@JoinColumn(name = "team_id")
private Team team;
...
}
@Entity
public class Team {
...
@Id
@GenerataionValue
@Column(name = "team_id")
private Long no;
@OneToMany(mappedBy = "team")
private List<User> user = new ArrayList<User>();
...
}
이렇게 팀에서도 OneToMany로 연관관계를 설정해준다.
그럼 User - N:1 - Team, Team - 1:N - User 이렇게 두개의 단방향 연관관계가 설정된다.
이 두 단방향 연관관계가 묶여 양방향 연관관계가 된다.
처음에는 양방향 연관관계는 user <-> Team 형식이라고 생각했지만 그게 아니라 User -> Team, Team -> User 형태로 두개의 단방향 연관관계를 묶어야 한다고 한다.
그럼 이제 여기서 mappedBy 속성이 추가되었다.
mappedBy에 대해 검색해보면 엔티티의 양방향 연관관계에서의 주인이 누구인지를 알려주는 옵션이라고 한다.
처음에 이거 보고 뭔소린가 했다...
mappedBy를 설명하기 전에 양방향 연관관계를 간단하게 설명한 이유가 여기있다.
위에서 JPA에서의 연관관계를 묶을때 단방향으로 설정하게 되면 한쪽에서는 조회가 되지만 한쪽에서는 조회할 수 없다고 했다.
즉, User에서는 속한 Team을 조회할 수 있지만 Team에서는 User를 조회할 수 없다.
하지만 데이터베이스에서 보면 Join을 통해 이것을 처리할 수 있다.
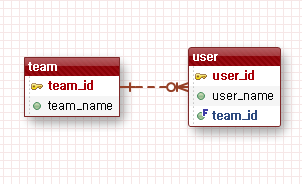
위에서와 동일하게 이런 테이블이 있다고 할 때
SELECT
u.user_name
, t.team_name
FROM
user u
inner join
team t
on u.team_id = t.team_id
WHERE
u.user_id = 1;
SELECT
u.user_name
, t.team_name
FROM
team t
inner join
user u
on t.team_id = u.team_id
WHERE
t.team_id = 1;이렇게 양쪽 테이블에서 서로에 대한 조회가 가능하다.
그래서 데이터베이스에서는 연관관계의 방향성이라는 것이 존재하지 않는다.
하지만 JPA에서는 객체를 참조하는 방식으로 두 엔티티의 연관관계를 찾게 된다.
User에서 team을 찾거나 Team에서 user를 찾게 할 수 있다.
아까 언급했듯이 JPA에서의 양방향 관계가 단방향 두개를 묶어놓은것과 마찬가지라는 것이 이런 의미이다.
그렇기 때문에 JPA에서는 외래키를 누가 관리할지를 명시해줘야 한다.
위 ERD를 기준으로 user테이블에 team_id라는 외래키를 관리하고 있으므로 user가 갖고 있는 team이 연관관계의 주인이라고 명시해야 한다는 것이다.
JPA에서는 mappedBy를 명시하지 않는다면 두 엔티티가 양방향 관계임을 모르게 된다.
@Entity
public class User {
...
@ManyToOne
@JoinColumn(name = "team_id")
private Team team;
...
}
@Entity
public class Team {
...
@Id
@GenerataionValue
@Column(name = "team_id")
private Long no;
@OneToMany(mappedBy = "team")
private List<User> user = new ArrayList<User>();
...
}그래서 이렇게 User에서 team이라는 외래키를 갖고 있게 하고 있으니 mappedBy로 외래키의 객체명을 작성해줘야 한다.
이제 여기까지는 여기저기 찾아보면서 알게된 내용들이고 이제부터는 인강 보면서 알게된 내용으로 정리.
@Entity
@NoArgsConstructor
@AllArgsConstructor
@Data
@ToString(CallSuper = true)
@EqualsAndHashCode(callSuper = true)
public class Book extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String category;
private Long authorId;
private Long publisherId;
@OneToOne
@ToString.Exclude
private BookReviewInfo bookReviewInfo;
}@Entity
@NoArgsConstructor
@Data
@ToString(callSuper = true)
@EqualsAndHashCode(callSuper = true)
public class BookReviewInfo extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@OneToOne(optional = false)
private Book book;
private float averageReviewScore;
private int reviewCount;
}@SpringBootTest
class BookReviewInfoRepositoryTest {
@Autowired
private BookReviewInfoRepository bookReviewInfoRepository;
@Autowired
private BookRepository bookRepository;
@Test
void crudTest() {
givenBookReviewInfo();
Book result = bookReviewInfoRepository
.findById(1L)
.orElseThrow(RuntimeException::new)
.getBook();
System.out.println("result : " + result);
BookReviewInfo result2 = bookRepository
.findById(1L)
.orElseThrow(RuntimeException::new)
.getBookReviewInfo();
System.out.println("result2 : " + result2);
}
private Book givenBook() {
Book book = new Book();
book.setName("new Book");
book.setAuthorId(1L);
book.setPublisherId(1L);
return bookRepository.save(book);
}
private void givenBookReviewInfo() {
BookReviewInfo bookReviewInfo = new BookReviewInfo();
bookReviewinfo.setBook(givenBook());
bookReviewinfo.setAverageReviewScore(4.5f);
bookReviewinfo.setReviewCount(2);
bookReviewInfoRepository.save(bookReviewInfo);
System.out.println(">>>>>>> " + bookReviewInfoRepository.findAll());
}
}
공부하다가 @OneToOne 하면서 mappedBy가 나왔기 때문에 다대일이 아닌 일대일로 정리.
일단 위 예제는 mappedBy를 붙이지 않고 테스트했다.
이대로 테스트를 하면 나머지는 다 제대로 출력되지만 result2는 null로 출력된다.
두 엔티티 모두 OneToOne으로 매핑해줬지만 bookReviewRepository를 통해 조회하는것은 정상 출력되나 bookRepository를 통해 조회하는 것은 null이 출력되는 것이다.
그래서 쿼리문을 확인해봤다.
select
book0_.id as id1_1_0_,
book0_.created_at as created_2_1_0_,
book0_.updated_at as updated_3_1_0_,
book0_.author_id as author_i4_1_0_,
book0_.book_review_info_id as book_rev8_1_0_,
book0_.category as category5_1_0_,
book0_.name as name6_1_0_,
book0_.publisher_id as publishe7_1_0_,
bookreview1_.id as id1_2_1_,
bookreview1_.created_at as created_2_2_1_,
bookreview1_.updated_at as updated_3_2_1_,
bookreview1_.average_review_score as average_4_2_1_,
bookreview1_.book_id as book_id6_2_1_,
bookreview1_.review_count as review_c5_2_1_,
book2_.id as id1_1_2_,
book2_.created_at as created_2_1_2_,
book2_.updated_at as updated_3_1_2_,
book2_.author_id as author_i4_1_2_,
book2_.book_review_info_id as book_rev8_1_2_,
book2_.category as category5_1_2_,
book2_.name as name6_1_2_,
book2_.publisher_id as publishe7_1_2_
from
book book0_
left outer join
book_review_info bookreview1_
on book0_.book_review_info_id=bookreview1_.id
left outer join
book book2_
on bookreview1_.book_id=book2_.id
where
book0_.id=?select 부분도 book이 두번 중복되어 있는 것을 볼 수 있고
조인 부분도 이상하다.
book과 reviewInfo를 left outer join으로 한번 조회하고 book을 book2로 또 만들어 다시 조인한다.
그리고 또하나. book 테이블에서도 review_info_id를 조회하고 있고 reviewInfo 테이블에서도 book_id를 조회하고 있다.
DB 테이블 구성을 생각해보면 아무래도 이상하다.
그럼 서로의 기본키를 서로 외래키로 갖고 있다는 얘기가 되니까.
그래서 디버그 모드로 돌려봤다.
book이 생성된 후와 bookReview가 생성된 후를 break point로 찍어 데이터베이스에 어떻게 들어가는지 봤더니
book이 생성될때는 bookReviewInfo가 존재하지 않으니 당연히 review_info_id가 null이 들어간다.
그럼 이 두 데이터를 추가했을때 데이터 상황은 아래와 같다.
| Book | |||||
| id | name | book_review_info | author_id | category | publisher_id |
| 1 | new Book | null | 1 | null | 1 |
| book_review_info | |||
| id | book_id | averageReviewScore | reviewCount |
| 1 | 1 | 4.5 | 2 |
그럼 테스트 코드를 봤을때 bookRepository.findById(1L).getBookReviewInfo(); 를 처리한다면
findById를 통해 저 데이터를 찾을 수는 있지만 getBookReviewInfo는 null로 되어있기 때문에 처리가 불가능해진다.
그리고 저 쿼리문만 보더라도 book.book_review_info_id = book_review_info.id 이 조인문에서 결과가 나올리가 없다.
그 뒤 조인은 말할것도 없고.
그래서 Book 엔티티에 mappedBy 속성을 추가해준다.
@Entity
@NoArgsConstructor
@AllArgsConstructor
@Data
@ToString(CallSuper = true)
@EqualsAndHashCode(callSuper = true)
public class Book extends BaseEntity {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
private String name;
private String category;
private Long authorId;
private Long publisherId;
@OneToOne(mappedBy = "book")
@ToString.Exclude
private BookReviewInfo bookReviewInfo;
}
그리고 동일하게 테스트를 실행 하면 결과가 달라진다.
result2도 잘 출력되고 쿼리문도 바뀐다.
select
book0_.id as id1_1_0_,
book0_.created_at as created_2_1_0_,
book0_.updated_at as updated_3_1_0_,
book0_.author_id as author_i4_1_0_,
book0_.category as category5_1_0_,
book0_.name as name6_1_0_,
book0_.publisher_id as publishe7_1_0_,
bookreview1_.id as id1_2_1_,
bookreview1_.created_at as created_2_2_1_,
bookreview1_.updated_at as updated_3_2_1_,
bookreview1_.average_review_score as average_4_2_1_,
bookreview1_.book_id as book_id6_2_1_,
bookreview1_.review_count as review_c5_2_1_
from
book book0_
left outer join
book_review_info bookreview1_
on book0_.id=bookreview1_.book_id
where
book0_.id=?book 테이블에서 review_info_id도 조회하지 않고 조인 역시 book_id로 조인하는걸로 변경되었다.
그럼 이 테스트로 알 수 있는것은 mappedBy를 선언하지 않게되면 양쪽 테이블 모두 서로의 Id를 외래키로 갖게 된다.
서로의 Id를 외래키로 갖게 되면 어느 한쪽은 null이 될 수 밖에 없고 그럼 다시 수정을 통해 넣어줘야 하는 상황이 생기게 된다.
mappedBy를 선언함으로서 외래키를 관리할 연관관계의 주인을 명시해줘서 해당 테이블에만 외래키가 존재하도록 하게된다.
여기서 관리한다는 것은 외래키를 등록하거나 수정하고 DB에 접속해 그 값을 바꿀 수 있다는 것을 의미한다.
즉, 연관관계의 주인이 아닌 객체에서 아무리 등록 혹은 수정 작업을 하더라도 DB에는 전혀 반영이 되지 않고 오직 읽기만 가능하다.
좀 정리해보자면 mappedBy는 양방향 연관관계의 주인을 명시하는 것이고 주인이란 두 연관관계에서의 외래키에 매핑되는 객체이다.
이 연관관계의 주인은 양방향 연관관계에서 외래키를 등록하거나 수정하고 DB에 접속해 값을 바꿀 수 있는 관리 권한이 있다고 보면 된다.
양방향 연관관계에서 mappedBy를 선언하지 않는다면 양쪽 테이블 모두 서로의 id를 외래키로 갖게 되고 JPA에서는 양방향 관계임을 모르게 되어 조회 처리가 제대로 이루어지지 않거나 단방향 조회만 가능해지게 된다.
처음에 무슨소린지 도통 모르겠어서 이해하는데도 시간이 엄청 걸리기도 했고 포스팅마다 여러번 읽어보면서 겨우 이해한 내용은 이정도...
분명 아직 모르는 부분이 많을거같은데 기본적인 개념은 이렇게 되는것 같고 여러 방법으로 사용해보면서 더 테스트해보며 알아봐야될것같다...
Reference
- 패스트캠퍼스 java/spring 초격차 패키지 Spring Data JPA
- 참고한 블로그
JPA 양방향 연관관계와 mappedBy
JPA를 공부하면서 가장 헷갈렸던 것 중 하나가 매핑이었다. 연관관계가 있는 두 엔티티를 어떻게 묶어야 하고, 어떤 어노테이션을 써야 했으며 주의해야 할 점은 무엇인지에 대해 간단히 정리해
velog.io
[JPA] 양방향 연관관계란 - Heee's Development Blog
Step by step goes a long way.
gmlwjd9405.github.io
[JPA] 양방향 연관관계
양방향 연관관계와 연관관계의 주인 Team을 통해서도 getMemberList()로 특정 팀에 속한 멤버 리스트를 가져오고 싶다. 객체 설계는 위와 같이 Member에서는 Team을 가지고 있고, Team에서는 Members를 가지
ict-nroo.tistory.com
'Spring' 카테고리의 다른 글
| IoC와 DI(2. IoC Container의 종류와 사용방법) (0) | 2022.08.18 |
|---|---|
| IoC와 DI(1. IoC Container란) (0) | 2022.08.18 |
| JPA Entity Listener 2 (0) | 2022.03.17 |
| JPA Entity Listener 1 (0) | 2022.03.16 |
| Jpa Entity 기본 Annotation 2 (@Column, @Transient) (0) | 2022.03.15 |