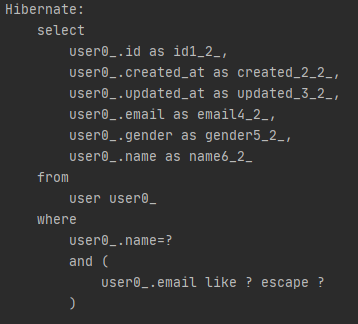
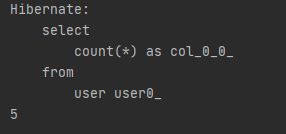
그리고 JPQL에서만 해당하는 것인지는 모르겠지만 해당 데이터가 존재하는지 유무에 대해 count()보다 existsById()를 사용하는것이 더 좋다는 포스팅을 봤다.
내용은 다음과 같았다.
데이터가 존재하는지를 확인하기 위해 count를 사용할 때가 있다.
count의 경우 총 개수를 확인해야 하기 때문에 존재유무와 상관없이 일단 모든 데이터를 훑어보게 된다.
하지만 exists의 경우 데이터가 존재하는지만 확인하면 되기 때문에 데이터를 찾는 순간 쿼리를 종료하게 된다.
그럼 당연히 존재유무만 확인하기 위해서는 count보다는 exists가 성능이 더 좋을 수 밖에 없다 라는 내용이다.
이 포스팅은 아래 Reference에서 확인.
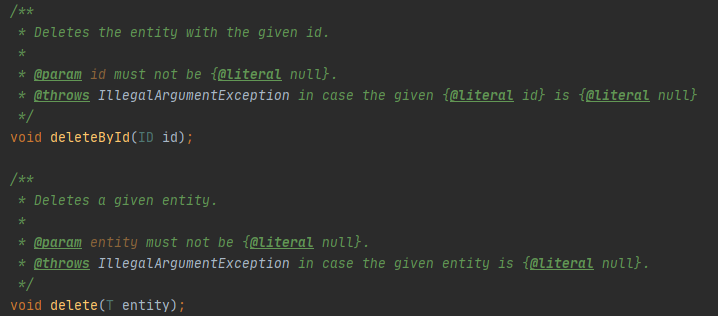
delete()
삭제 메소드이다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
User user = userRepository.findById(1L).orElseThrow(RuntimeException::new);
userRepository.delete(user);
userRepository.findAll().forEach(System.out::println);
}
여기서 주의해야할 점은 상황에 따라 달라지겠지만 위 예제처럼 진행하는 경우 findById().orElse() 보다는
findById().orElseThrow가 좀 더 낫다.
delete의 경우 CrudRepository에서 확인해보면 'entity must not be {@literal null}.' 이라고 있는것을 볼 수 있는데
null이 들어올 경우 문제가 발생한다는 것이다.
실제로 null을 넣어보면 IllegalArgumentException이 발생하는 것을 볼 수 있다.
그래서 그냥 orElseThrow로 null인 경우 Exception을 바로 발생시키게 하는것.
그냥 편의성 정도로 생각하면 될것같다.
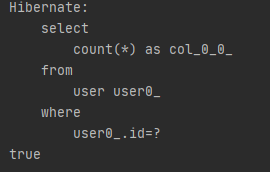
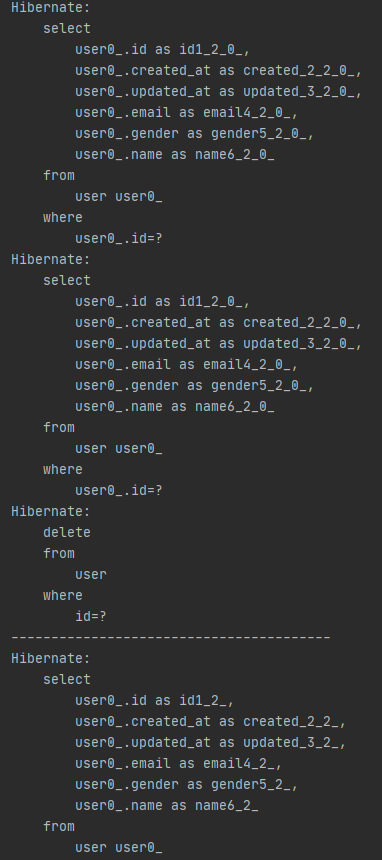
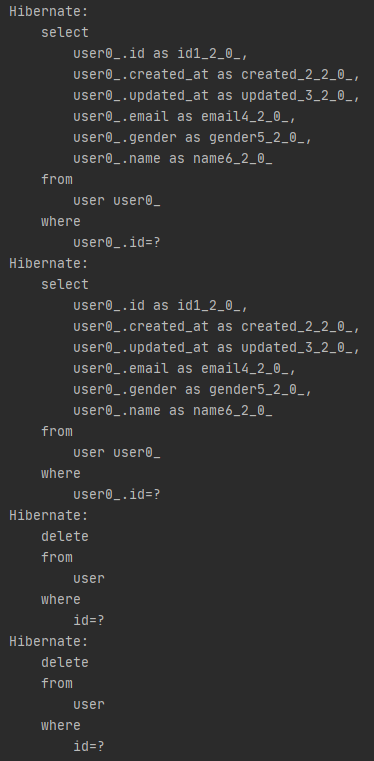
쿼리문은 이렇게 로그에 출력된다.
첫 select 는 findById()에 의해 실행된 select문이다.
그리고 그 아래에 select문이 한번 더 실행된것을 볼 수 있는데 delete()메소드의 경우 delete쿼리를 실행하기 전 select로 해당 데이터가 있는지 조회한 다음에 있으면 delete쿼리를 실행하기 때문이다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
//존재하지 않는 데이터를 만들기 위해 new로 생성
User user = new User();
user.setId(8L);
userRepository.delete(user);
userRepository.findAll().forEach(System.out::println);
}
그래서 위 코드처럼 현재 없는 아이디값을 넣어 테스트해보면 delete쿼리는 실행되지 않고 select쿼리까지만 실행되는것을 볼 수 있다.
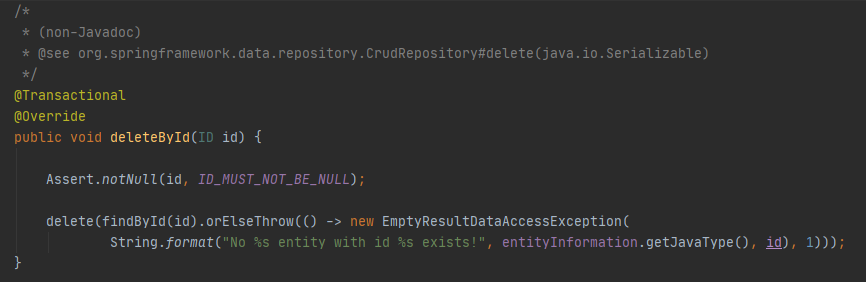
CrudRepository를 보면 delete() 메소드는 entity를 받는 반면 deleteById() 메소드는 메소드명처럼 id를 받는다.
결과는 delete() 메소드와 동일한 결과를 출력해준다.
쿼리문에서의 차이는 findById() 메소드를 사용하지 않기 때문에 delete 처리 하기 전 select문이 하나 줄어들었다는 정도다.
SimpleJpaRepository에서 deleteById를 보면 넘어온 id값으로 findById를 사용해 delete()에 넘겨줄 데이터를 조회하는데 데이터가 null인경우에는 EmptyResultDataAccessException을 발생시키고 존재하는 경우 delete()에 id값을 인자로 호출하고 있다.
이전 포스팅인 상단 기초에서 아주 간단한 설정 및 엔티티 어노테이션, 그리고 앞으로 사용하게 될 메소드가 정의되어 있는 위치를 확인했다.
Repository 인터페이스를 생성하고 거기서 상속받는 JpaRepository는 PagingAndSortingRepository를 상속받으며 이 인터페이스 또한 CrudRepository라는 인터페이스를 상속받는다.
JpaRepository를 상속받지 않고 CrudRepository를 상속받아도 될 정도로 많은 메소드가 정의되어 있다고 했는데
공부한 내용은 JpaRepository를 상속받아서 사용했고 CrudRepository안에 있는 메소드들이 JpaRepository를 통해서도
사용할 수 있기 때문에 JpaRepository만 뜯어본다!
일단 공부한 환경은 아래와 같다.
Intelli J
SpringBoot 2.6.2
Lombok
Gradle 7.3.2
JpaRepository와 CrudRepository에 주석으로 각 메소드들에 대한 설명들이 적혀 있지만 좀 정리하고자 한다.
이 포스팅에서는 아래 메소드들만 정리.
save()
saveAll()
saveAndFlush()
saveAllAndFlush()
getOne()
findById()
findAll()
findAllById()
save()
save()는 의미 그대로 엔티티를 저장하고자 할 때 사용하는 메소드이다.
가장 기초적으로 사용하는 방법은 아래와 같다.
@Data
@NoArgsConstructor
@AllArgsConstructor
@RequiredArgsConstructor
@Entity
public class User{
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@NonNull
private String name;
@NonNull
private String email;
}
public interface UserRepository extends JpaRepository<User, Long>{
}
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
User user = new User();
user.setName("coco");
user.setEmail("coco@gmail.com");
userRepository.save(user);
}
이렇게 save 메소드는 User 엔티티를 받아 저장해준다.
강의에서는 H2-in-memory DB를 사용했고 별도로 MySQL에서도 테스트했기 때문에 User Entity의 GeneratedValue는
IDENTITY로 설정.
이 테스트를 실행하게 되면 User 테이블에 name = 'coco', email = 'coco@gmail.com' 이렇게 insert 된다.
그리고 Id의 경우는 GeneratedValue에 의해 1씩 증가하며 저장되게 된다.
그리고 CrudRepository안에 있는 메소드들을 보면 update에 대한 메소드는 보이지 않는다.
Create는 save, Read 는 find, Delete는 delete로 메소드가 정의되어 있는것을 볼 수 있는데 Update 메소드는 찾을 수 없다.
그 Update에 대한 처리를 진행하는 것이 save 메소드의 역할 중 하나이기 때문이다.
save 메소드는 새로운 데이터를 넣는 경우 insert로 동작하게 되지만 기존에 있는 데이터를 넣게 되면 update 쿼리를 실행하게 된다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
User user = new User();
user.setName("coco");
user.setEmail("coco@gmail.com");
//insert
userRepository.save(user);
//update
User user2 = userRepository.findById(1L).orElseThrow(RuntimeException::new);
user2.setEmail("coco1@gmail.com");
userRepository.save(user2);
}
이 테스트를 실행하면 name='coco', email='coco@gmail.com' 이라는 데이터가 저장된다.
그리고 user2 에서 사용한 findById는 Id값으로 데이터를 찾아온다는 것인데 where id = 1 이렇게 생각하면 쉽다.
현재 User Entity에서 Id는 id라는 Long 타입의 필드로 명시되어 있기 때문에 Long 타입으로 1L을 넣어주는것.
orElseThrow의 경우는 Jpa에서 Repository에서 리턴타입을 Optional로 받을 수 있도록 지원하기 때문이고
Optional은 null로 인한 예외 처리를 해줘야 한다.
즉, userRepository.findById(1L)은 리턴 타입이 Optional<T> 이기 때문에 null이었을 때 발생할 예외처리를 해줘야 한다는 것이다.
강의에서 orElseThrow를 계속 사용하셨기에 동일하게 작성했지만 orElse(), orElseGet() 등 여러 Optional 메소드가 존재한다.
이것은 따로 정리가 필요...
일단 Optional에 대한 포스팅은 하단 Reference에서 확인.
그럼 코드를 다시 보자면 user2는 findById로 Id가 1L인 데이터를 가져왔기 때문에 테스트 초반 저장된
name='coco', email='coco@gmail.com' 을 의미하게 된다.
그리고 setEmail로 coco1@gmail.com 으로 데이터를 변경해준 뒤 save를 해주게 되면 update가 수행되게 된다.
이 때 로그를 확인해 쿼리를 확인하게 되면 insert로 user 테이블에 데이터를 저장해준 뒤
select로 조회를 2번 진행한다. 그리고 update 쿼리가 수행된것을 볼 수 있다.
첫번째 save(user)로 인해 insert 쿼리가 실행되고 findById(1L)로 select 쿼리가 한번 실행된 후에
save(user2)가 실행되면서 select 쿼리로 조회한번 한 뒤에 update 쿼리가 실행되는 것이다.
코드만 봤을때는 동일한 save이지만 insert와 update를 알아서 구분해 처리해준 것이다.
어떻게 이렇게 수행되는지 보려면 SimpleJpaRepository에서 확인해야 한다.
Intelli J - window 기준 Shift 두번 눌러서 SimpleJpaRepository 검색하면 들어가서 볼 수 있다.
확인해야 하는 부분은 이 부분.
그리고 SimpleJpaRepository는 JpaRepositoryImplementation을 재정의 하고 있고
JpaRepositoryImplementation은 JpaRepository를 상속받고 있다.
즉, JpaRepository에 정의된 메소드들은 SimpleJpaRepository에서 구현체를 제공하고 있다는 것이다.
save()메소드는 제일 먼저 null 체크를 하게 되는데 entity로 받은 인자가 null이면 오류가 발생하게 된다.
그리고 if문으로 isNew 즉, 새로운 데이터면 em(Entity Manager)에서 insert(persist)를 수행한다.
새로운 데이터가 아닌 경우는 Entity Manager에서 update(merge)를 수행하도록 구현되어 있다.
isNew라는 것은 주어진 Entity가 새로운것인지에 대한 여부이기 때문에 코드 그대로
새로운 데이터라면 persist를, 존재하는 데이터라면 merge를 수행하도록 구현한 것이다.
isNew에 대해 좀 더 보기 위해 AbstractPersistable에 들어가서 보게 되면
isNew에 대한 리턴은 null == getId가 된다.
entity에서 Id로 지정해둔 필드가 null 이라면 새로운 데이터라는 조건이 되는것이고
null이 아니라면 존재하는 데이터이기 때문에 update를 처리하도록 하는것이다.
saveAll()
saveAll() 메소드는 의미 그대로 단일 데이터가 아닌 복수의 데이터를 저장하는것이다.
Lists.newArrayList를 통해 저장할 수 있다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
void crudTest(){
User user = new User();
user.setName("coco");
user.setEmail("coco@gmail.com");
User user2 = new User();
user.setName("mozzi");
user.setEmail("mozzi@gmail.com");
userRepository.saveAll(Lists.newArrayList(user, user2);
}
saveAndFlush(), saveAllANdFlush()
saveAndFlush는 save와 flush를 수행하는 메소드이다.
save는 위에서 설명했으니 생략하고 flush에 대해 먼저 간단하게 설명.
Transaction commit이 일어날 때 flush가 동작하게 되는데 이때 insert, update, delete SQL들이 DB로 넘어간다.
이때 영속성 컨텍스트(Persistence Context)를 비우는것은 아니고 DB와 동기화 한다고 이해하면 된다.
예를들어 user테이블에 insert한 뒤에 다시 set으로 내용을 수정한다면 수정된 Entity를 쓰기 지연 SQL 저장소에 등록해 두었다가 이 쿼리를 DB에 전송한다. 전송이 발생하는것을 flush가 발생한 시점이라고 볼 수 있고 flush가 일어난 다음에 실제 commit이 일어나게 된다.
flush에 대한 자세한것은 Reference에서 참고.
flush는 이러한 동작을 하게 되지만 saveAndFlush에 있는 flush는 DB에 업데이트를 하는 flush가 아니라
영속성 컨텍스트내의 한 공간에 flush를 해 저장해 두었다가 Transaction이 종료되는 시점에 DB에 업데이트하는 형태다.
결과만 놓고 봤을때는 save() 메소드와 동일한 결과를 보여준다.
하지만 과정에서의 차이가 존재하는건데 하나의 테스트에서 save()나 saveAndFlush()를 한번 한 뒤에 데이터를 수정했을때, 그 과정에서의 차이가 발생한다.
최초 insert의 과정은 무조건 Context내의 한 공간에 업데이트가 되는것은 동일하다.
이 한 공간을 space라고 임의로 정했을 때, saveAndFlush()를 통해 업데이트를 진행하게 되면 매번 그 업데이트 쿼리를 space에 보내고 Transaction이 종료되는 시점에 DB에 업데이트를 하게 된다.
하지만 save는 Context에 마지막으로 존재하는 형태의 데이터를 query로 만들어서 Transaction 종료 시점에 DB에 업데이트 하게 된다.
즉, save는 context에 마지막으로 남아있는 데이터만 넘겨줄 쿼리를 한번 생성해 업데이트를 해주지만
saveAndFlush는 업데이트가 한번 발생할때마다 space에 쿼리를 만들어 보내놓고 처리하는 과정인것.
그렇기 때문에 효율성 측면에서는 save가 flush보다 더 낫다고 한다.
하지만 그렇다고 saveAndFlush가 무조건 더 안좋은것은 아니고 환경 혹은 때에 따라 saveAndFlush가 더 좋은 경우가 있다고 한다.
flush에 대해 아직 깊게 알지 못하기 때문에 이부분은 더 공부가 필요...
그리고 saveAndFlush에 대해 테스트를 많이 진행해서 그 과정을 포스팅 해주신 분들이 많으니
Reference를 참고해 볼것.
saveAllAndFlush는 saveAll()과 save()의 차이처럼 한번에 여러개의 데이터를 처리하는 차이이므로 설명은 생략.
getOne()
getOne() 메소드는 Id(primary key)를 통해 매칭되는 하나의 객체를 가져오는 메소드다.
결과만 놓고 봤을때는 findById() 메소드와 동일한 결과를 보여주는데 getOne은 내부적으로
EntityManager.getReference() 를 통해 엔티티를 가져오게 되어있다.
LazyLoading을 지원하고 호출되는 시점에는 일단 Proxy를 가져오며 실제로 가져온 Entity의 속성에 접근하는
순간 DB에 접근하는 방식을 사용한다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
@Transactional
void crudTest(){
User user = userRepository.getOne(1L);
System.out.println(user);
}
findById()
findById() 메소드는 getOne처럼 Id를 통해 매칭되는 하나의 객체를 가져오는 메소드이다.
getOne은 Proxy를 먼저 가져온 후에 속성에 접근하는 순간 DB에 접근하는 방식이라고 했는데
findById는 DB를 바로 조회해서 필요한 데이터를 가져온다. 그래서 반환되는 객체 역시 데이터가 매핑되어 있는 실제
Entity 객체이다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
@Transactional
void crudTest(){
Optional<User> user = userRepository.findById(1L);
System.out.println(user);
User user2 = userRepository.findById(1L).orElse(null);
// orElse는 값이 있다면 값을 반환하고 없다면
// ( ) 안에 명시한 다른 값을 반환한다.
// 단 " " 를 통한 문자열 반환은 할 수 없다.
System.out.println(user2);
}
위와 같은 형태로 사용할 수 있는데 findById는 Optional 타입으로 사용하거나 Entity 타입으로 사용할 수 있다.
findAll()
findAll() 메소드는 해당 테이블의 모든 데이터를 List로 가져오는 메소드이다.
쿼리문으로 보면 Select * from User 이런 느낌.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
@Transactional
void crudTest(){
userRepository.findAll().forEach(System.out::println);
//forEach의 경우 가져온 리스트를 라인별로 출력하기 위해 사용한것.
//name을 기준으로 내림차순 정렬
List<User> users = userRepository.findAll(Sort.by(Sort.Direction.DESC, "name"));
users.forEach(System.out::println);
}
이렇게 테이블의 모든 데이터를 가져올 수 있으며 Sort를 추가해 정렬된 데이터를 가져올 수 있다.
그래서 쿼리문 역시 order by user_.name desc 로 동작하는것을 로그에서 볼 수 있다.
findAllById()
findAllById는 여러개의 Id값을 통해 해당 데이터들을 조회하는 메소드이다.
예를들어 각각 1, 3, 5라는 Id값을 갖고 있는 3개의 데이터를 가져오려고 할때 사용한다.
@SpringBootTest
class UserRepositoryTest{
@Autowired
private UserRepository userRepository;
@Test
@Transactional
void crudTest(){
//Id 값이 1, 3, 5인 데이터를 가져오기
List<User> users = userRepository.findAllById(Lists.newArrayList(1L, 3L, 5L);
users.forEach(System.out::println);
//아래와 같이 Id 값을 처리할 수도 있다.
List<Long> ids = new ArrayList<>();
ids.add(1L);
ids.add(2L);
ids.add(3L);
List<User> users2 = userRepository.findAllById(ids);
users2.forEach(System.out::println);
}
이렇게 실행하게 되면 각각 1, 3, 5의 Id 값을 갖고 있는 3개의 데이터가 출력된다.
그래서 위와 같이 AccessLevel을 protected로 설정해 최대한 기본 생성자를 감추도록 해야 한다.
이렇게 해도 문제가 발생하지 않는 이유는 jpa에서 protected 수준의 기본 생성자까지는 찾을 수 있기 때문이라고 한다.
@RequiredArgsConstructor를 명시해야 하는 경우도 있다.
이 어노테이션의 경우 꼭 필요한 인자만 받는 생성자인데 일반적으로는 아무 설정 없이 사용한다면 NoArgsConstructor와 동일하게 동작한다.
필수로 받아야 하는 인자에 대한 명시가 없기 때문인데 그래서 꼭 사용해야 하는 경우가 null이 되면 안되는 필드가 존재할때다.
@NonNull이라는 어노테이션이 존재하는데 이 경우 의미 그대로 null이 되면 안된다는 것이다.
그럼 이렇게 NonNull 어노테이션을 명시한 필드가 존재한다면 NoArgsConstructor는 동작할 수 없게 된다.
@AllArgsConstructor의 경우는 모든 인자를 받아야 하는 생성자이기 때문에 @RequiredArgsConstructor가 필요하게 되는것이다.
조금 난해한 점은 @Data, @NoArgsConstructor, @AllArgsConstructor 이렇게 하면 Data 어노테이션 내부에 RequiredArgsConstructor가 있기 때문에 잘 될것 같지만 생성자를 찾을 수 없다는 오류가 발생해 @RequiredArgsConstructor를 다시 명시해줘야 한다.
왜 이러는지 찾아봤지만 언급되어 있는 포스팅을 찾지 못했다.....
좀 정리하자면 필드 중 null이 되면 안되는 필드가 존재한다고 했을 때 해당 필드에 @NonNull을 붙여주고 이때의 생성자 처리는 NoArgsConstructor로 해결할 수 없기 때문에 NonNull 필드를 필수로 받게 되는 RequiredArgsConstructor를 명시해 줘야 한다. 단, Data 안에 있더라도 왜인지 알 수 없지만 오류가 발생하기 때문에 다시 명시해줘야 한다.
EqualsAndHashCode의 경우 강의 에서는 jpa에서 사용할일은 별로 없으나 자바에서 기본적으로 객체의 동등성을 비교하기 위해 사용하는것을 권고하고 있다고 했다.
하지만 '객체를 set에 저장한 뒤 필드 값을 변경하면 hashCode가 변경되면서 이전에 저장한 객체를 찾을 수 없다는 문제가 발생하기도 한다' 라는 이유로 지양해야 한다는 글도 봤다.
그래서 이 어노테이션에 대해서는 좀 더 공부가 필요할것 같다.
마지막으로 @Builder 어노테이션인데 필드값을 주입해주는데 Builder의 형식을 갖고 제공하는 것이다.
User user = User.builder()
.name("aa")
.email("aa@gmail.com")
.build();
이런 형태로 사용한다. setName(), setEmail로 필드값을 주입하는것과 동일한 결과를 갖는다.
다시 Entity의 Primary key 부분으로 돌아온다.
@Data
@NoArgsConstructor
@AllArgsConstructor
@Entity
public class User{
@Id
@GeneratedValue
private Long id;
}
primary key는 String으로 한다거나 뭐 여러가지 방법이 많겠지만 공부하는 완전 초반에만 해도 MySQL에서 Auto Increment나 Oracle에서 Sequence를 통해 자동 증가를 많이 사용했었다.
사실 편하기도하고...
그래서 Id는 Long타입으로 설정하고 자동 증가하도록 작성한 예제다.
이때 자동 생성해주는 어노테이션이 @GeneratedValue인데 위에서 언급한것처럼 MySQL의 Auto Increment나 Oracle의 Sequence.NEXT_VAL 같은 형태다.
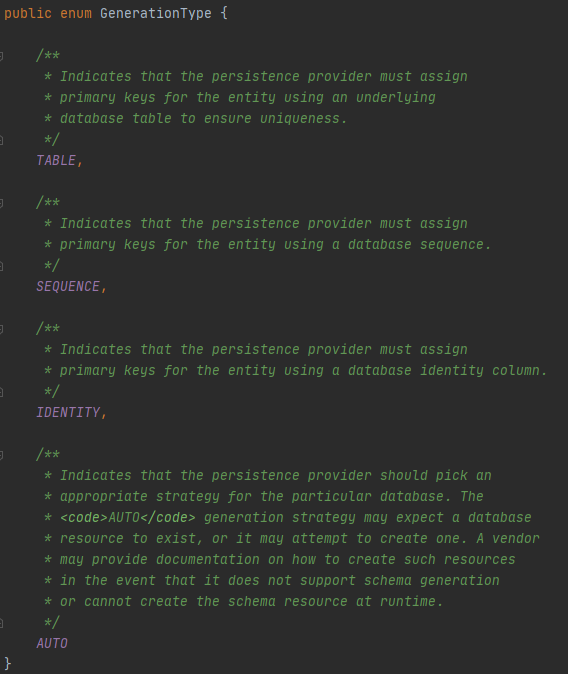
이 어노테이션의 경우 default로 AUTO를 갖고 있다.
strategy로 전략을 변경할 수 있는데 설정할 수 있는 경우는 아래와 같다.
AUTO의 경우는 DB 종류에 따라 JPA가 알맞은것을 선택하게 된다.
IDENTITY는 기본 키 생성을 데이터베이스에 위임하는것인데 MySQL, SQL Server, DB2에서 사용이 가능하다.
SEQUENCE는 데이터베이스 시퀀스를 사용해서 기본키를 할당하는 것으로 Oracle, PostgreSQL, DB2, H2에서 사용한다.
마지막으로 TABLE은 키 생성 전용 테이블을 만들어서 sequence 처럼 사용하는 것이다.
하지만 TABLE은 모든 데이터 베이스에서 사용이 가능하지만 최적화 되어 있지 않은 테이블을 사용하기에 성능문제에 이슈가 있다.
그럼 이제 Entity에 대한 제일 기초적인 내용은 끝이다.
그럼 이제 Entity 객체를 저장하고 조회하기 위해서는 Repository가 필요하다.
Repository는 interface로 생성하며 JpaRepository를 상속받아 사용한다.
JpaRepository의 경우는 제네릭 타입으로 <Entity, IdType>을 받는다.
그래서 User Entity에 대한 Repository는 아래와 같이 작성한다.
public interface UserRepository extends JpaRepository<User, Long>{
}
이렇게 JpaRepository를 상속받는 것으로 상단 이미지에 보이는 JpaRepository의 많은 메소드들을 활용해 여러 기능들을 사용할 수 있다.
그리고 JpaRepository는 또 PagingAndSortingRepository와 QueryByExampleExecutor를 상속받고 있는 것을 볼 수 있다.
이 인터페이스들 역시 들어가서 확인해보면 여러 메소드들을 사용할 수 있다는 것을 볼 수 있고
PaingAndSortingRepository는 CrudRepository를 또 상속받고 있다.
그래서 이렇게 확인해보면 결국 CrudRepository에 정의 되어 있는 메소드들이 기본적으로 사용하게 될 메소드들이라는 것을 알 수 있다.
JpaRepository가 아닌 CrudRepository를 상속받아 사용해도 될 정도로 많은 메소드들이 정의 되어 있다.
CrudRepository는 Repository 인터페이스를 상속받고 있는데 이 인터페이스의 경우는 최상위 Repository이며 아무것도 존재하지 않는다.
이 인터페이스는 Jpa에서 사용하는 domain Repository 타입이라는 것을 알려주기 위한 인터페이스이고 실제 메소드에 대한 정의는 존재하지 않는다.
그럼 이제 여기까지가 기본적인 Entity와 Repository 설정 및 생성 그리고 확인해야 할 부분이고